3.5 뉴스 기사 분류: 다중 분류 문제
import keras
keras.__version__
Using TensorFlow backend.
'2.3.1'
이 절에서 로이터(Reuter) 뉴스를 46개의 상호 배타적인 토픽으로 분류하는 신경망을 만들어 보겠습니다. 클래스가 많기 때문에 이 문제는 다중 분류(multiclass classification)의 예입니다. 각 데이터 포인트가 정확히 하나의 범주로 분류되기 때문에 좀 더 정확히 말하면 단일 레이블, 다중 분류(single-label, multiclass classification) 문제입니다. 각 데이터 포인트가 여러 개의 범주(예를 들어 토픽)에 속할 수 있다면 이것은 다중 레이블 다중 분류(multi-label, multiclass classification) 문제가 됩니다.
3.5.1 로이터 데이터셋
1986년에 로이터에서 공개한 짧은 뉴스 기사와 토픽의 집합인 로이터 데이터셋을 사용하겠습니다.1 이 데이터셋은 텍스트 분류를 위해 널리 사용되는 간단한 데이터셋입니다. 46개의 토픽이 있으며 어떤 토픽은 다른 것에 비해 데이터가 많습니다. 각 토픽은 훈련 세트에 최소한 10개의 샘플을 가지고 있습니다.
IMDB, MNIST와 마찬가지로 로이터 데이터셋은 케라스에 포함되어 있습니다. 한번 살펴보죠.
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
IMDB 데이터셋처럼 num_words=10000 매개변수는 데이터에서 가장 자주 등장하는 단어 1만 개 로 제한합니다.
여기에는 8,982개의 훈련 샘플과 2,246개의 테스트 샘플이 있습니다.2
len(train_data)
8982
len(test_data)
2246
IMDB 리뷰처럼 각 샘플은 정수 리스트입니다(단어 인덱스).
train_data[10]
[1,
245,
273,
207,
156,
53,
74,
160,
26,
14,
46,
296,
26,
39,
74,
2979,
3554,
14,
46,
4689,
4329,
86,
61,
3499,
4795,
14,
61,
451,
4329,
17,
12]
궁금한 경우를 위해 어떻게 단어로 디코딩하는지 알아보겠습니다.
# word_index는 단어와 정수 인덱스를 매핑한 딕셔너리입니다.
word_index = reuters.get_word_index()
# 정수 인덱스와 단어를 매핑하도록 뒤집습니다.
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# 리뷰를 디코딩합니다. 0, 1, 2는 ‘패딩’, ‘문서 시작’, ‘사전에 없음’을 위한 인덱스이므로 3을 뺍니다.
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
print(decoded_newswire)
? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3
샘플에 연결된 레이블은 토픽의 인덱스로 0과 45 사이의 정수입니다.
train_labels[10]
3
3.5.2 데이터 준비
이전의 예제와 동일한 코드를 사용해서 데이터를 벡터로 변환합니다.3
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
# 훈련 데이터 벡터 변환
x_train = vectorize_sequences(train_data)
# 테스트 데이터 벡터 변환
x_test = vectorize_sequences(test_data)
레이블을 벡터로 바꾸는 방법은 두 가지입니다. 레이블의 리스트를 정수 텐서로 변환하는 것과 원–핫 인코딩을 사용하는 것입니다. 원–핫 인코딩이 범주형 데이터에 널리 사용되기 때문에 범주형 인코딩(categorical encoding)이라고도 부릅니다. 원–핫 인코딩에 대한 자세한 설명은 6.1절을 참고하세요. 이 경우 레이블의 원–핫 인코딩은 각 레이블의 인덱스 자리는 1이고 나머지는 모두 0인 벡터입니다. 다음과 같습니다.4
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
# 훈련 레이블 벡터 변환
one_hot_train_labels = to_one_hot(train_labels)
# 테스트 레이블 벡터 변환
one_hot_test_labels = to_one_hot(test_labels)
MNIST 예제에서 이미 보았듯이 케라스에는 이를 위한 내장 함수가 있습니다.
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
3.5.3 모델 구성
이 토픽 분류 문제는 이전의 영화 리뷰 분류 문제와 비슷해 보입니다. 두 경우 모두 짧은 텍스트를 분류하는 것이죠. 여기에서는 새로운 제약 사항이 추가되었습니다. 출력 클래스의 개수가 2에서 46개로 늘어난 점입니다. 출력 공간의 차원이 훨씬 커졌습니다.
이전에 사용했던 것처럼 Dense 층을 쌓으면 각 층은 이전 층의 출력에서 제공한 정보만 사용할 수 있습니다. 한 층이 분류 문제에 필요한 일부 정보를 누락하면 그다음 층에서 이를 복원할 방법이 없습니다. 각 층은 잠재적으로 정보의 병목(information bottleneck)이 될 수 있습니다. 이전 예제에서 16차원을 가진 중간층을 사용했지만 16차원 공간은 46개의 클래스를 구분하기에 너무 제약이 많을 것 같습니다. 이렇게 규모가 작은 층은 유용한 정보를 완전히 잃게 되는 정보의 병목 지점처럼 동작할 수 있습니다.
이런 이유로 좀 더 규모가 큰 층을 사용하겠습니다. 64개의 유닛을 사용해 보죠.
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
이 구조에서 주목해야 할 점이 두 가지 있습니다.
- 마지막
Dense층의 크기가 46입니다. 각 입력 샘플에 대해서 46차원의 벡터를 출력한다는 뜻입니다. 이 벡터의 각 원소(각 차원)는 각기 다른 출력 클래스가 인코딩된 것입니다. - 마지막 층에
softmax활성화 함수가 사용되었습니다. MNIST 예제에서 이런 방식을 보았습니다. 각 입력 샘플마다 46개의 출력 클래스에 대한 확률 분포를 출력합니다. 즉, 46차원의 출력 벡터를 만들며output[i]는 어떤 샘플이 클래스 i에 속할 확률입니다. 46개의 값을 모두 더하면 1이 됩니다.
이런 문제에 사용할 최선의 손실 함수는 categorical_crossentropy입니다. 이 함수는 두 확률 분포 사이의 거리를 측정합니다. 여기에서는 네트워크가 출력한 확률 분포와 진짜 레이블의 분포 사이의 거리입니다. 두 분포 사이의 거리를 최소화하면 진짜 레이블에 가능한 가까운 출력을 내도록 모델을 훈련하게 됩니다.
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['acc'])
3.5.4 훈련 검증
훈련 데이터에서 1,000개의 샘플을 따로 떼어서 검증 세트로 사용하겠습니다.
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
이제 20번의 에포크로 모델을 훈련시킵니다.
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 1s 183us/step - loss: 2.6579 - acc: 0.5184 - val_loss: 1.7557 - val_acc: 0.6590
Epoch 2/20
7982/7982 [==============================] - 1s 119us/step - loss: 1.4318 - acc: 0.7053 - val_loss: 1.3306 - val_acc: 0.7040
Epoch 3/20
7982/7982 [==============================] - 1s 108us/step - loss: 1.0671 - acc: 0.7732 - val_loss: 1.1466 - val_acc: 0.7570
Epoch 4/20
7982/7982 [==============================] - 1s 116us/step - loss: 0.8429 - acc: 0.8211 - val_loss: 1.0458 - val_acc: 0.7680
Epoch 5/20
7982/7982 [==============================] - 1s 118us/step - loss: 0.6735 - acc: 0.8571 - val_loss: 0.9852 - val_acc: 0.7930
Epoch 6/20
7982/7982 [==============================] - 1s 101us/step - loss: 0.5369 - acc: 0.8870 - val_loss: 0.9195 - val_acc: 0.8100
Epoch 7/20
7982/7982 [==============================] - 1s 106us/step - loss: 0.4343 - acc: 0.9074 - val_loss: 0.9023 - val_acc: 0.8070
Epoch 8/20
7982/7982 [==============================] - 1s 102us/step - loss: 0.3583 - acc: 0.9245 - val_loss: 0.8817 - val_acc: 0.8090
Epoch 9/20
7982/7982 [==============================] - 1s 108us/step - loss: 0.2912 - acc: 0.9389 - val_loss: 0.8943 - val_acc: 0.8110
Epoch 10/20
7982/7982 [==============================] - 1s 106us/step - loss: 0.2457 - acc: 0.9420 - val_loss: 0.8973 - val_acc: 0.8130
Epoch 11/20
7982/7982 [==============================] - 1s 105us/step - loss: 0.2112 - acc: 0.9483 - val_loss: 0.9249 - val_acc: 0.8090
Epoch 12/20
7982/7982 [==============================] - 1s 106us/step - loss: 0.1868 - acc: 0.9491 - val_loss: 0.9583 - val_acc: 0.8070
Epoch 13/20
7982/7982 [==============================] - 1s 108us/step - loss: 0.1667 - acc: 0.9525 - val_loss: 0.9374 - val_acc: 0.8100
Epoch 14/20
7982/7982 [==============================] - 1s 102us/step - loss: 0.1506 - acc: 0.9558 - val_loss: 0.9587 - val_acc: 0.8100
Epoch 15/20
7982/7982 [==============================] - 1s 114us/step - loss: 0.1416 - acc: 0.9570 - val_loss: 0.9815 - val_acc: 0.8090
Epoch 16/20
7982/7982 [==============================] - 1s 116us/step - loss: 0.1317 - acc: 0.9557 - val_loss: 1.0173 - val_acc: 0.8040
Epoch 17/20
7982/7982 [==============================] - 1s 112us/step - loss: 0.1247 - acc: 0.9567 - val_loss: 1.0434 - val_acc: 0.8010
Epoch 18/20
7982/7982 [==============================] - 1s 122us/step - loss: 0.1204 - acc: 0.9565 - val_loss: 1.0958 - val_acc: 0.8040
Epoch 19/20
7982/7982 [==============================] - 1s 108us/step - loss: 0.1147 - acc: 0.9585 - val_loss: 1.0221 - val_acc: 0.8040
Epoch 20/20
7982/7982 [==============================] - 1s 108us/step - loss: 0.1112 - acc: 0.9589 - val_loss: 1.0438 - val_acc: 0.8140
마지막으로 손실과 정확도 곡선을 그립니다(그림 3-9와 그림 3-10 참고).
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
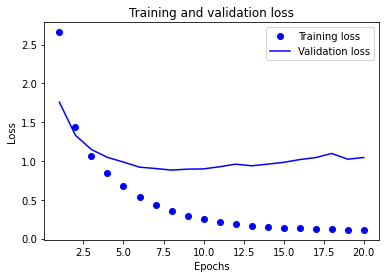
그림 3-9. 훈련과 검증 손실
plt.clf() # 그래프를 초기화합니다
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
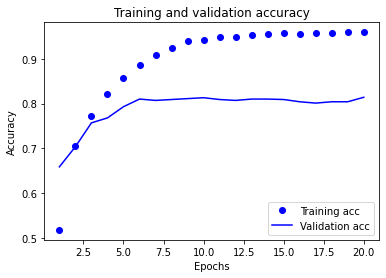
그림 3-10. 훈련과 검증 정확도
이 모델은 9번째 에포크 이후에 과대적합이 시작됩니다. 9번의 에포크로 새로운 모델을 훈련하고 테스트 세트에서 평가하겠습니다:
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['acc'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
Train on 7982 samples, validate on 1000 samples
Epoch 1/9
7982/7982 [==============================] - 1s 113us/step - loss: 2.5724 - acc: 0.5474 - val_loss: 1.7010 - val_acc: 0.6430
Epoch 2/9
7982/7982 [==============================] - 1s 104us/step - loss: 1.4067 - acc: 0.7072 - val_loss: 1.3188 - val_acc: 0.7170
Epoch 3/9
7982/7982 [==============================] - 1s 105us/step - loss: 1.0724 - acc: 0.7690 - val_loss: 1.1656 - val_acc: 0.7510
Epoch 4/9
7982/7982 [==============================] - 1s 113us/step - loss: 0.8479 - acc: 0.8191 - val_loss: 1.0445 - val_acc: 0.7870
Epoch 5/9
7982/7982 [==============================] - 1s 108us/step - loss: 0.6775 - acc: 0.8596 - val_loss: 0.9880 - val_acc: 0.7900
Epoch 6/9
7982/7982 [==============================] - 1s 106us/step - loss: 0.5387 - acc: 0.8886 - val_loss: 0.9434 - val_acc: 0.8080
Epoch 7/9
7982/7982 [==============================] - 1s 111us/step - loss: 0.4338 - acc: 0.9060 - val_loss: 0.9055 - val_acc: 0.8160
Epoch 8/9
7982/7982 [==============================] - 1s 106us/step - loss: 0.3478 - acc: 0.9255 - val_loss: 0.9154 - val_acc: 0.8020
Epoch 9/9
7982/7982 [==============================] - 1s 103us/step - loss: 0.2925 - acc: 0.9344 - val_loss: 0.9180 - val_acc: 0.8130
2246/2246 [==============================] - 0s 180us/step
results
[0.9947754672246646, 0.7818343639373779]
대략 78%의 정확도를 달성했습니다. 균형 잡힌 이진 분류 문제에서 완전히 무작위로 분류하면 50%의 정확도를 달성합니다. 이 문제는 불균형한 데이터셋을 사용하므로 무작위로 분류하면 19% 정도를 달성합니다. 여기에 비하면 이 결과는 꽤 좋은 편입니다.
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
float(np.sum(hits_array)) / len(test_labels)
0.1834372217275156
3.5.5 새로운 데이터에 대해 예측하기
모델 인스턴스의 predict 메서드는 46개의 토픽에 대한 확률 분포를 반환합니다. 테스트 데이터 전체에 대한 토픽을 예측해 보겠습니다.
predictions = model.predict(x_test)
predictions의 각 항목은 길이가 46인 벡터입니다.
predictions[0].shape
(46,)
이 벡터의 원소 합은 1입니다.
np.sum(predictions[0])
0.9999999
가장 큰 값이 예측 클래스가 됩니다. 즉, 가장 확률이 높은 클래스입니다.
np.argmax(predictions[0])
3
3.5.6 레이블과 손실을 다루는 다른 방법
앞서 언급한 것처럼 레이블을 인코딩하는 다른 방법은 다음과 같이 정수 텐서로 변환하는 것입니다.5
y_train = np.array(train_labels)
y_test = np.array(test_labels)
이 방식을 사용하려면 손실 함수 하나만 바꾸면 됩니다. 코드3 –21에 사용된 손실 함수 categorical_crossentropy는 레이블이 범주형 인코딩되어 있을 것이라고 기대합니다. 정수 레이블을 사용할 때는 sparse_categorical_crossentropy를 사용해야 합니다.
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['acc'])
이 손실 함수는 인터페이스만 다를 뿐이고 수학적으로는 categorical_crossentropy와 동일합니다.
3.5.7 충분히 큰 중간층을 두어야 하는 이유
앞서 언급한 것처럼 마지막 출력이 46차원이기 때문에 중간층의 히든 유닛이 46개보다 많이 적어서는 안 됩니다. 46차원보다 훨씬 작은 중간층(예를 들어 4차원)을 두면 정보의 병목이 어떻게 나타나는지 확인해 보겠습니다.
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['acc'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
Train on 7982 samples, validate on 1000 samples
Epoch 1/20
7982/7982 [==============================] - 1s 140us/step - loss: 2.6045 - acc: 0.3259 - val_loss: 2.0093 - val_acc: 0.4090
Epoch 2/20
7982/7982 [==============================] - 1s 133us/step - loss: 1.7757 - acc: 0.5437 - val_loss: 1.6368 - val_acc: 0.5980
Epoch 3/20
7982/7982 [==============================] - 1s 132us/step - loss: 1.4455 - acc: 0.6310 - val_loss: 1.4710 - val_acc: 0.6380
Epoch 4/20
7982/7982 [==============================] - 1s 139us/step - loss: 1.2326 - acc: 0.6706 - val_loss: 1.3755 - val_acc: 0.6660
Epoch 5/20
7982/7982 [==============================] - 1s 133us/step - loss: 1.0808 - acc: 0.7194 - val_loss: 1.3239 - val_acc: 0.6940
Epoch 6/20
7982/7982 [==============================] - 1s 134us/step - loss: 0.9672 - acc: 0.7434 - val_loss: 1.3140 - val_acc: 0.6990
Epoch 7/20
7982/7982 [==============================] - 1s 133us/step - loss: 0.8801 - acc: 0.7578 - val_loss: 1.3034 - val_acc: 0.7080
Epoch 8/20
7982/7982 [==============================] - 1s 140us/step - loss: 0.8074 - acc: 0.7696 - val_loss: 1.3217 - val_acc: 0.7000
Epoch 9/20
7982/7982 [==============================] - 1s 144us/step - loss: 0.7477 - acc: 0.7876 - val_loss: 1.3796 - val_acc: 0.7010
Epoch 10/20
7982/7982 [==============================] - 1s 131us/step - loss: 0.6964 - acc: 0.8047 - val_loss: 1.3602 - val_acc: 0.7150
Epoch 11/20
7982/7982 [==============================] - 1s 135us/step - loss: 0.6503 - acc: 0.8222 - val_loss: 1.4246 - val_acc: 0.7130
Epoch 12/20
7982/7982 [==============================] - 1s 134us/step - loss: 0.6096 - acc: 0.8378 - val_loss: 1.4503 - val_acc: 0.7260
Epoch 13/20
7982/7982 [==============================] - 1s 125us/step - loss: 0.5713 - acc: 0.8469 - val_loss: 1.5091 - val_acc: 0.7160
Epoch 14/20
7982/7982 [==============================] - 1s 140us/step - loss: 0.5425 - acc: 0.8519 - val_loss: 1.5723 - val_acc: 0.7180
Epoch 15/20
7982/7982 [==============================] - 1s 142us/step - loss: 0.5142 - acc: 0.8530 - val_loss: 1.6621 - val_acc: 0.7190
Epoch 16/20
7982/7982 [==============================] - 1s 130us/step - loss: 0.4895 - acc: 0.8562 - val_loss: 1.6391 - val_acc: 0.7220
Epoch 17/20
7982/7982 [==============================] - 1s 148us/step - loss: 0.4700 - acc: 0.8591 - val_loss: 1.7543 - val_acc: 0.7120
Epoch 18/20
7982/7982 [==============================] - 1s 172us/step - loss: 0.4496 - acc: 0.8639 - val_loss: 1.7692 - val_acc: 0.7130
Epoch 19/20
7982/7982 [==============================] - 1s 159us/step - loss: 0.4355 - acc: 0.8672 - val_loss: 1.8469 - val_acc: 0.7100
Epoch 20/20
7982/7982 [==============================] - 1s 137us/step - loss: 0.4229 - acc: 0.8712 - val_loss: 1.8837 - val_acc: 0.7060
<keras.callbacks.callbacks.History at 0x1adecfa8888>
검증 정확도의 최고 값은 약 71%로 8% 정도 감소되었습니다. 이런 손실의 원인 대부분은 많은 정보(클래스 46개의 분할 초평면을 복원하기에 충분한 정보)를 중간층의 저차원 표현 공간으로 압축하려고 했기 때문입니다. 이 네트워크는 필요한 정보 대부분을 4차원 표현 안에 구겨 넣었지만 전부는 넣지 못했습니다.
3.5.8 추가 실험
- 더 크거나 작은 층을 사용해 보세요.32개의 유닛,128개의 유닛 등
- 여기에서 2개의 은닉 층을 사용했습니다. 1개나 3개의 은닉 층을 사용해 보세요.
3.5.9 정리
다음은 이 예제에서 배운 것들입니다.
- N개의 클래스로 데이터 포인트를 분류하려면 네트워크의 마지막
Dense층의 크기는N이어야 합니다. - 단일 레이블, 다중 분류 문제에서는 N개의 클래스에 대한 확률 분포를 출력하기 위해
softmax활성화 함수를 사용해야 합니다. - 이런 문제에는 항상 범주형 크로스엔트로피를 사용해야 합니다. 이 함수는 모델이 출력한 확률 분포와 타깃 분포 사이의 거리를 최소화합니다.
- 다중 분류에서 레이블을 다루는 두 가지 방법이 있습니다.
- 레이블을 범주형 인코딩(또는 원–핫 인코딩)으로 인코딩하고
categorical_crossentropy손실 함수를 사용합니다. - 레이블을 정수로 인코딩하고
sparse_categorical_crossentropy손실 함수를 사용합니다. - 많은 수의 범주를 분류할 때 중간층의 크기가 너무 작아 네트워크에 정보의 병목이 생기지 않도록 해야 합니다.
-
이 데이터셋은 원본 로이터 데이터셋의 135개 토픽 중에서 샘플이 많은 것을 뽑아 간단하게 만든 것입니다. 이 데이터셋의 토픽은 금융과 관련된 카테고리입니다. ↩
-
로이터와 3.6절의 보스턴 주택 가격 데이터셋은 load_data() 함수에서 test_split 매개변수로 테스트 데이터의 크기를 조절할 수 있습니다. 기본값은 0.2로 전체 데이터 중 20%를 테스트 데이터로 만듭니다. ↩
-
IMDB와 로이터 데이터셋은 미리 전체 데이터셋의 단어를 고유한 정수 인덱스로 바꾼 후에 훈련 데이터와 테스트 데이터로 나누어 놓은 것입니다. 일반적으로는 훈련 데이터에서 구축한 어휘 사전으로 테스트 세트를 변환합니다. 이렇게 하는 이유는 실전에서 샘플에 어떤 텍스트가 들어 있을지 알 수 없기 때문에 테스트 세트의 어휘를 이용하면 낙관적으로 테스트 세트를 평가하는 셈이 되기 때문입니다. ↩
-
to_one_hot()함수는labels매개변수를 제외하고는 앞에 정의된vectorize_sequences()와 동일합니다.train_data와test_data는 파이썬 리스트의 넘파이 배열이기 때문에to_categorical()함수를 사용하지 못합니다.x_train과x_test의 크기는 각각 (8982, 10000), (2246, 10000)이 되고one_hot_train_labels와one_hot_test_labels의 크기는 각각 (8982, 46), (2246, 46)이 됩니다. ↩ -
사실
train_labels와test_labels는 정수 타입의 넘파이 배열이기 때문에 다시np.array()함수를 사용할 필요는 없습니다.np.array()함수는np.asarray()함수와 동일하지만 입력된 넘파이 배열의 복사본을 만들어 반환합니다. ↩
댓글남기기