4.4 과대적합과 과소적합
import keras
keras.__version__
Using TensorFlow backend.
'2.3.1'
이전 장에 있던 세 가지 예제인 영화 리뷰 예측, 토픽 분류, 주택 가격 회귀 모두 홀드아웃 데이터에서 모델의 성능이 몇 번의 에포크 후에 최고치에 다다랐다가 감소되기 시작했습니다. 즉 모델이 금방 훈련 데이터에 과대적합(overfitting)되기 시작합니다. 과대적합은 모든 머신 러닝 문제에서 발생합니다. 머신 러닝을 마스터하려면 과대적합을 다루는 방법을 꼭 배워야 합니다.
머신 러닝의 근본적인 이슈는 최적화와 일반화 사이의 줄다리기입니다. 최적화(optimization)는 가능한 훈련 데이터에서 최고의 성능을 얻으려고 모델을 조정하는 과정입니다(머신 러닝의 학습). 반면에 일반화(generalization)는 훈련된 모델이 이전에 본 적 없는 데이터에서 얼마나 잘 수행되는지 의미합니다. 물론 모델을 만드는 목적은 좋은 일반화 성능을 얻는 것입니다. 하지만 일반화 성능을 제어할 방법이 없습니다. 단지 훈련 데이터를 기반으로 모델을 조정할 수만 있습니다.
훈련 초기에 최적화와 일반화는 상호 연관되어 있습니다. 훈련 데이터의 손실이 낮아질수록 테스트 데이터의 손실도 낮아집니다. 이런 상황이 발생할 때 모델이 과소적합(underfitting)되었다고 말합니다. 모델의 성능이 계속 발전될 여지가 있습니다. 즉 네트워크가 훈련 데이터에 있는 관련 특성을 모두 학습하지 못했습니다. 하지만 훈련 데이터에 여러 번 반복 학습하고 나면 어느 시점부터 일반화 성능이 더 이상 높아지지 않습니다. 검증 세트의 성능이 멈추고 감소되기 시작합니다. 즉 모델이 과대적합되기 시작합니다. 이는 훈련 데이터에 특화된 패턴을 학습하기 시작했다는 의미입니다. 이 패턴은 새로운 데이터와 관련성이 적어 잘못된 판단을 하게 만듭니다.
모델이 관련성이 없고 좋지 못한 패턴을 훈련 데이터에서 학습하지 못하도록 하려면 가장 좋은 방법은 더 많은 훈련 데이터를 모으는 것입니다. 더 많은 데이터에서 훈련된 모델은 자연히 일반화 성능이 더욱 뛰어납니다. 데이터를 더 모으는 것이 불가능할 때 차선책은 모델이 수용할 수 있는 정보의 양을 조절하거나 저장할 수 있는 정보에 제약을 가하는 것입니다. 네트워크가 적은 수의 패턴만 기억할 수 있다면 최적화 과정에서 가장 중요한 패턴에 집중하게 될 것입니다. 이런 패턴은 더 나은 일반화 성능을 제공할 수 있습니다.
이런 식으로 과대적합을 피하는 처리 과정을 규제(regularization)라고 합니다. 가장 널리 사용되는 규제 기법을 알아보고 3.4절에서 본 영화 리뷰 분류 모델에 실제로 적용하여 성능을 향상시켜 보겠습니다.1
노트
이 노트북에서는 편의상 IMDB 테스트 세트를 검증 세트로 사용합니다.
3장 5절에 있는 코드를 사용해 데이터를 준비합니다.
from keras.datasets import imdb
import numpy as np
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
def vectorize_sequences(sequences, dimension=10000):
# 크기가 (len(sequences), dimension))이고 모든 원소가 0인 행렬을 만듭니다
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # results[i]에서 특정 인덱스의 위치를 1로 만듭니다
return results
# 훈련 데이터를 벡터로 변환합니다
x_train = vectorize_sequences(train_data)
# 테스트 데이터를 벡터로 변환합니다
x_test = vectorize_sequences(test_data)
# 레이블을 벡터로 변환합니다
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
4.4.1 네트워크 크기 축소
과대적합을 막는 가장 단순한 방법은 모델의 크기, 즉 모델에 있는 학습 파라미터의 수를 줄이는 것입니다. 파라미터의 수는 층의 수와 각 층의 유닛 수에 의해 결정됩니다. 딥러닝에서 모델에 있는 학습 파라미터의 수를 종종 모델의 용량(capacity)이라고 말합니다. 당연하게 파라미터가 많은 모델이 기억 용량이 더 많습니다. 훈련 샘플과 타깃 사이를 딕셔너리 같은 일대일 매핑으로 완벽하게 학습할 수도 있습니다. 이런 매핑은 일반화 능력이 없습니다. 예를 들어 50만 개의 이진 파라미터가 있는 모델은 MNIST 훈련 세트의 숫자 이미지 클래스를 모두 쉽게 학습할 수 있습니다. 5만 개의 숫자 이미지 하나마다 10개의 이진 파라미터만 있으면 됩니다. 하지만 이런 모델은 새로운 숫자 샘플을 분류하는 용도로는 쓸모가 없습니다. 항상 유념해야 할 것은 딥러닝 모델은 훈련 데이터에 잘 맞추려는 경향이 있다는 점입니다. 하지만 진짜 문제는 최적화가 아니고 일반화입니다.
다른 한편으로 네트워크가 기억 용량에 제한이 있다면 이런 매핑을 쉽게 학습하지 못할 것입니다. 따라서 손실을 최소화하기 위해 타깃에 대한 예측 성능을 가진 압축된 표현을 학습해야 합니다. 정확히 이런 표현이 우리 관심 대상입니다. 동시에 기억해야 할 것은 과소적합되지 않도록 충분한 파라미터를 가진 모델을 사용해야 한다는 점입니다. 모델의 기억 용량이 부족해서는 안 됩니다. 너무 많은 용량과 충분하지 않은 용량 사이의 절충점을 찾아야 합니다.
안타깝지만 알맞은 층의 수나 각 층의 유닛 수를 결정할 수 있는 마법 같은 공식은 없습니다. 데이터에 알맞은 모델 크기를 찾으려면 각기 다른 구조를 (당연히 테스트 세트가 아니고 검증 세트에서) 평가해 보아야 합니다. 적절한 모델 크기를 찾는 일반적인 작업 흐름은 비교적 적은 수의 층과 파라미터로 시작합니다. 그다음 검증 손실이 감소되기 시작할 때까지 층이나 유닛의 수를 늘리는 것입니다.
영화 리뷰 분류 모델에 적용해 보죠. 원래 네트워크는 다음과 같습니다.
# 코드 4-3. 원본 모델
from keras import models
from keras import layers
original_model = models.Sequential()
original_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
original_model.add(layers.Dense(16, activation='relu'))
original_model.add(layers.Dense(1, activation='sigmoid'))
original_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
더 작은 네트워크로 바꾸어 보죠.
# 코드 4-4. 작은 용량의 모델
smaller_model = models.Sequential()
smaller_model.add(layers.Dense(6, activation='relu', input_shape=(10000,)))
smaller_model.add(layers.Dense(6, activation='relu'))
smaller_model.add(layers.Dense(1, activation='sigmoid'))
smaller_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
원본 네트워크와 축소된 네트워크의 검증 손실을 비교해 보죠. 점으로 표현된 것이 작은 네트워크이고 덧셈 기호가 원래 네트워크 입니다(검증 손실이 작은 것이 좋은 모델입니다)(그림 4-4 참고).
original_hist = original_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 3s 117us/step - loss: 0.4440 - acc: 0.8251 - val_loss: 0.3286 - val_acc: 0.8835
Epoch 2/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.2573 - acc: 0.9078 - val_loss: 0.2864 - val_acc: 0.8882
Epoch 3/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.1991 - acc: 0.9292 - val_loss: 0.2821 - val_acc: 0.8891
Epoch 4/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.1666 - acc: 0.9412 - val_loss: 0.2939 - val_acc: 0.8844
Epoch 5/20
25000/25000 [==============================] - 2s 84us/step - loss: 0.1435 - acc: 0.9501 - val_loss: 0.3116 - val_acc: 0.8804
Epoch 6/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.1257 - acc: 0.9558 - val_loss: 0.3483 - val_acc: 0.8721
Epoch 7/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1104 - acc: 0.9615 - val_loss: 0.3598 - val_acc: 0.8722
Epoch 8/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0977 - acc: 0.9669 - val_loss: 0.3975 - val_acc: 0.8662
Epoch 9/20
25000/25000 [==============================] - 2s 84us/step - loss: 0.0841 - acc: 0.9721 - val_loss: 0.4339 - val_acc: 0.8611
Epoch 10/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0755 - acc: 0.9757 - val_loss: 0.4997 - val_acc: 0.8524
Epoch 11/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0684 - acc: 0.9778 - val_loss: 0.4872 - val_acc: 0.8587
Epoch 12/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0563 - acc: 0.9831 - val_loss: 0.5220 - val_acc: 0.8557
Epoch 13/20
25000/25000 [==============================] - 2s 80us/step - loss: 0.0513 - acc: 0.9843 - val_loss: 0.5351 - val_acc: 0.8579
Epoch 14/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0423 - acc: 0.9881 - val_loss: 0.6093 - val_acc: 0.8501
Epoch 15/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0363 - acc: 0.9894 - val_loss: 0.6115 - val_acc: 0.8558
Epoch 16/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0310 - acc: 0.9909 - val_loss: 0.6426 - val_acc: 0.8536
Epoch 17/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0265 - acc: 0.9926 - val_loss: 0.7694 - val_acc: 0.8417
Epoch 18/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0208 - acc: 0.9946 - val_loss: 0.7221 - val_acc: 0.8516
Epoch 19/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0198 - acc: 0.9949 - val_loss: 0.7739 - val_acc: 0.8476
Epoch 20/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0151 - acc: 0.9965 - val_loss: 0.9725 - val_acc: 0.8298
smaller_model_hist = smaller_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 2s 87us/step - loss: 0.5670 - acc: 0.7410 - val_loss: 0.4849 - val_acc: 0.8256
Epoch 2/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3924 - acc: 0.8895 - val_loss: 0.3609 - val_acc: 0.8780
Epoch 3/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.2791 - acc: 0.9174 - val_loss: 0.3012 - val_acc: 0.8879
Epoch 4/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.2213 - acc: 0.9278 - val_loss: 0.2823 - val_acc: 0.8900
Epoch 5/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1877 - acc: 0.9375 - val_loss: 0.2816 - val_acc: 0.8863
Epoch 6/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1649 - acc: 0.9448 - val_loss: 0.2858 - val_acc: 0.8856
Epoch 7/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1467 - acc: 0.9518 - val_loss: 0.2954 - val_acc: 0.8817
Epoch 8/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1330 - acc: 0.9558 - val_loss: 0.3067 - val_acc: 0.8796
Epoch 9/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1196 - acc: 0.9620 - val_loss: 0.3223 - val_acc: 0.8773
Epoch 10/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.1095 - acc: 0.9648 - val_loss: 0.3358 - val_acc: 0.8752
Epoch 11/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0988 - acc: 0.9690 - val_loss: 0.3549 - val_acc: 0.8712
Epoch 12/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0898 - acc: 0.9728 - val_loss: 0.3790 - val_acc: 0.8692
Epoch 13/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0816 - acc: 0.9759 - val_loss: 0.3900 - val_acc: 0.8676
Epoch 14/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0743 - acc: 0.9772 - val_loss: 0.4130 - val_acc: 0.8654
Epoch 15/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0675 - acc: 0.9806 - val_loss: 0.4395 - val_acc: 0.8631
Epoch 16/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0605 - acc: 0.9829 - val_loss: 0.4665 - val_acc: 0.8603
Epoch 17/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0554 - acc: 0.9840 - val_loss: 0.4742 - val_acc: 0.8618
Epoch 18/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.0500 - acc: 0.9868 - val_loss: 0.5050 - val_acc: 0.8590
Epoch 19/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0456 - acc: 0.9883 - val_loss: 0.5209 - val_acc: 0.8591
Epoch 20/20
25000/25000 [==============================] - 2s 83us/step - loss: 0.0408 - acc: 0.9896 - val_loss: 0.5726 - val_acc: 0.8534
epochs = range(1, 21)
original_val_loss = original_hist.history['val_loss']
smaller_model_val_loss = smaller_model_hist.history['val_loss']
import matplotlib.pyplot as plt
# ‘b+’는 파란색 덧셈 기호을 의미합니다
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
# ‘bo’는 파란색 점을 의미합니다
plt.plot(epochs, smaller_model_val_loss, 'bo', label='Smaller model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
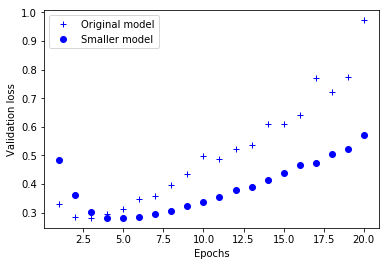
그림 4-4. 검증 손실에 대한 모델 용량의 효과: 작은 용량의 모델과 비교
여기서 볼 수 있듯이 작은 네트워크가 기본 네트워크보다 더 나중에 과대적합되기 시작했습니다(네 번째 에포크가 아니라 여섯 번째 에포크에서). 과대적합이 시작되었을 때 성능이 더 천천히 감소되었습니다.
이번에는 문제에 필요한 것보다 훨씬 더 많은 용량을 가진 네트워크를 비교해 보겠습니다.
# 코드 4-5 큰 용량의 모델
bigger_model = models.Sequential()
bigger_model.add(layers.Dense(1024, activation='relu', input_shape=(10000,)))
bigger_model.add(layers.Dense(1024, activation='relu'))
bigger_model.add(layers.Dense(1, activation='sigmoid'))
bigger_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
bigger_model_hist = bigger_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 3s 133us/step - loss: 0.5454 - acc: 0.7882 - val_loss: 0.2760 - val_acc: 0.8891
Epoch 2/20
25000/25000 [==============================] - 3s 111us/step - loss: 0.2188 - acc: 0.9147 - val_loss: 0.3125 - val_acc: 0.8754
Epoch 3/20
25000/25000 [==============================] - 2s 100us/step - loss: 0.1151 - acc: 0.9607 - val_loss: 0.3470 - val_acc: 0.8831
Epoch 4/20
25000/25000 [==============================] - 3s 105us/step - loss: 0.0658 - acc: 0.9850 - val_loss: 0.4694 - val_acc: 0.8829
Epoch 5/20
25000/25000 [==============================] - 2s 96us/step - loss: 0.0979 - acc: 0.9854 - val_loss: 0.4798 - val_acc: 0.8785
Epoch 6/20
25000/25000 [==============================] - 3s 105us/step - loss: 0.0027 - acc: 0.9996 - val_loss: 0.6154 - val_acc: 0.8806
Epoch 7/20
25000/25000 [==============================] - 2s 98us/step - loss: 8.7515e-04 - acc: 0.9998 - val_loss: 0.7370 - val_acc: 0.8802
Epoch 8/20
25000/25000 [==============================] - 3s 108us/step - loss: 0.1479 - acc: 0.9849 - val_loss: 0.8596 - val_acc: 0.8716
Epoch 9/20
25000/25000 [==============================] - 3s 104us/step - loss: 9.8797e-04 - acc: 0.9998 - val_loss: 0.7918 - val_acc: 0.8764
Epoch 10/20
25000/25000 [==============================] - 3s 102us/step - loss: 3.0235e-05 - acc: 1.0000 - val_loss: 0.8231 - val_acc: 0.8813
Epoch 11/20
25000/25000 [==============================] - 2s 97us/step - loss: 4.1083e-06 - acc: 1.0000 - val_loss: 0.9013 - val_acc: 0.8801
Epoch 12/20
25000/25000 [==============================] - 3s 104us/step - loss: 0.1174 - acc: 0.9915 - val_loss: 1.0090 - val_acc: 0.8724
Epoch 13/20
25000/25000 [==============================] - 2s 95us/step - loss: 6.8146e-04 - acc: 1.0000 - val_loss: 0.9307 - val_acc: 0.8774
Epoch 14/20
25000/25000 [==============================] - 2s 95us/step - loss: 0.1304 - acc: 0.9871 - val_loss: 1.0209 - val_acc: 0.8652
Epoch 15/20
25000/25000 [==============================] - 3s 105us/step - loss: 0.0512 - acc: 0.9931 - val_loss: 2.1249 - val_acc: 0.7613
Epoch 16/20
25000/25000 [==============================] - 2s 99us/step - loss: 0.0201 - acc: 0.9975 - val_loss: 0.8756 - val_acc: 0.8756
Epoch 17/20
25000/25000 [==============================] - 2s 98us/step - loss: 1.0459e-05 - acc: 1.0000 - val_loss: 0.9152 - val_acc: 0.8774
Epoch 18/20
25000/25000 [==============================] - 3s 101us/step - loss: 1.5831e-06 - acc: 1.0000 - val_loss: 0.9598 - val_acc: 0.8780
Epoch 19/20
25000/25000 [==============================] - 2s 97us/step - loss: 3.9690e-07 - acc: 1.0000 - val_loss: 1.0252 - val_acc: 0.8777
Epoch 20/20
25000/25000 [==============================] - 3s 103us/step - loss: 1.6289e-07 - acc: 1.0000 - val_loss: 1.0794 - val_acc: 0.8782
다음은 더 큰 네트워크가 기본 네트워크에 비해 얼마나 차이나는지를 보여줍니다. 점이 용량이 큰 네트워크의 검증 손실이고 덧셈 기호는 원본 네트워크의 검증 손실입니다(그림 4-5 참고).
bigger_model_val_loss = bigger_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, bigger_model_val_loss, 'bo', label='Bigger model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
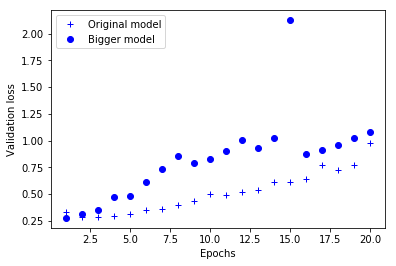
그림 4-5. 검증 손실에 대한 모델 용량의 효과: 큰 용량의 모델과 비교
용량이 큰 네트워크는 첫 번째 에포크 이후 거의 바로 과대적합이 시작되어 갈수록 더 심해집니다. 검증 손실도 매우 불안정합니다.
다음은 두 네트워크의 훈련 손실입니다:
original_train_loss = original_hist.history['loss']
bigger_model_train_loss = bigger_model_hist.history['loss']
plt.plot(epochs, original_train_loss, 'b+', label='Original model')
plt.plot(epochs, bigger_model_train_loss, 'bo', label='Bigger model')
plt.xlabel('Epochs')
plt.ylabel('Training loss')
plt.legend()
plt.show()
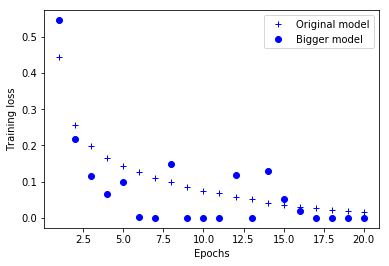
그림 4-6. 훈련 손실에 대한 모델 용량의 효과: 큰 용량의 모델과 비교)
여기서 볼 수 있듯이 용량이 큰 네트워크는 훈련 손실이 매우 빠르게 0에 가까워집니다. 용량이 많은 네트워크일수록 더 빠르게 훈련 데이터를 모델링할 수 있습니다(결국 훈련 손실이 낮아집니다). 하지만 더욱 과대적합에 민감해집니다(결국 훈련과 검증 손실 사이에 큰 차이가 발생합니다).
4.4.2 가중치 규제 추가
오캄의 면도날(Occam’s razor) 이론을 알고 있을지 모르겠습니다. 어떤 것에 대한 두 가지의 설명이 있다면 더 적은 가정이 필요한 간단한 설명이 옳을 것이라는 이론입니다. 이 개념은 신경망으로 학습되는 모델에도 적용됩니다. 어떤 훈련 데이터와 네트워크 구조가 주어졌을 때 데이터를 설명할 수 있는 가중치 값의 집합은 여러 개(여러 개의 모델)입니다. 간단한 모델이 복잡한 모델보다 덜 과대적합될 가능성이 높습니다.
여기에서 간단한 모델은 파라미터 값 분포의 엔트로피가 작은 모델입니다(또는 앞 절에서 본 것처럼 적은 수의 파라미터를 가진 모델입니다). 그러므로 과대적합을 완화하기 위한 일반적인 방법은 네트워크의 복잡도에 제한을 두어 가중치가 작은 값을 가지도록 강제하는 것입니다. 가중치 값의 분포가 더 균일하게 됩니다. 이를 가중치 규제(weight regularization)라고 하며, 네트워크의 손실 함수에 큰 가중치에 연관된 비용을 추가합니다. 두 가지 형태의 비용이 있습니다.
-
L1 규제: 가중치의 절댓값에 비례하는 비용이 추가됩니다(가중치의 L1 노름(norm)).
-
L2 규제: 가중치의 제곱에 비례하는 비용이 추가됩니다(가중치의 L2 노름2). L2 규제는 신경망에서 가중치 감쇠(weight decay)라고도 부릅니다. 이름이 다르지만 혼동하지 마세요. 가중치 감쇠는 수학적으로 L2 규제와 동일합니다.
케라스에서 가중치 규제 객체3를 층의 키워드 매개변수로 전달하여 가중치 규제를 추가할 수 있습니다. 영화 리뷰 분류 네트워크에 L2 가중치 규제를 추가해 보죠.
# 코드 4-6. 모델에 L2 가중치 추가하기
from keras import regularizers
l2_model = models.Sequential()
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu', input_shape=(10000,)))
l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001),
activation='relu'))
l2_model.add(layers.Dense(1, activation='sigmoid'))
l2_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
l2(0.001)는 가중치 행렬의 모든 원소를 제곱하고 0.001을 곱하여 네트워크의 전체 손실에 더해진다는 의미입니다. 이 페널티(penalty) 항은 훈련할 때만 추가됩니다.4 이 네트워크의 손실은 테스트보다 훈련할 때 더 높을 것입니다.
그림 4-7은 L2 규제 페널티의 효과를 보여 줍니다. 여기서 볼 수 있듯이 두 모델이 동일한 파라미터 수를 가지고 있더라도 L2 규제를 사용한 모델(점)이 기본 모델(덧셈 기호)보다 훨씬 더 과대적합에 잘 견디고 있습니다.
l2_model_hist = l2_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 2s 68us/step - loss: 0.4879 - acc: 0.8152 - val_loss: 0.3895 - val_acc: 0.8656
Epoch 2/20
25000/25000 [==============================] - 2s 68us/step - loss: 0.3100 - acc: 0.9061 - val_loss: 0.3306 - val_acc: 0.8891
Epoch 3/20
25000/25000 [==============================] - 2s 61us/step - loss: 0.2657 - acc: 0.9202 - val_loss: 0.3301 - val_acc: 0.8872
Epoch 4/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2459 - acc: 0.9286 - val_loss: 0.3413 - val_acc: 0.8821
Epoch 5/20
25000/25000 [==============================] - 2s 68us/step - loss: 0.2323 - acc: 0.9352 - val_loss: 0.3818 - val_acc: 0.8685
Epoch 6/20
25000/25000 [==============================] - 2s 64us/step - loss: 0.2237 - acc: 0.9390 - val_loss: 0.3676 - val_acc: 0.8752
Epoch 7/20
25000/25000 [==============================] - 2s 61us/step - loss: 0.2173 - acc: 0.9409 - val_loss: 0.3748 - val_acc: 0.8735
Epoch 8/20
25000/25000 [==============================] - 1s 60us/step - loss: 0.2106 - acc: 0.9445 - val_loss: 0.3726 - val_acc: 0.8752
Epoch 9/20
25000/25000 [==============================] - 2s 69us/step - loss: 0.2045 - acc: 0.9466 - val_loss: 0.3762 - val_acc: 0.8753
Epoch 10/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2009 - acc: 0.9500 - val_loss: 0.3822 - val_acc: 0.8748
Epoch 11/20
25000/25000 [==============================] - 1s 60us/step - loss: 0.1950 - acc: 0.9495 - val_loss: 0.3838 - val_acc: 0.8755
Epoch 12/20
25000/25000 [==============================] - 2s 69us/step - loss: 0.1922 - acc: 0.9518 - val_loss: 0.3918 - val_acc: 0.8745
Epoch 13/20
25000/25000 [==============================] - 2s 66us/step - loss: 0.1876 - acc: 0.9548 - val_loss: 0.3972 - val_acc: 0.8734
Epoch 14/20
25000/25000 [==============================] - 2s 68us/step - loss: 0.1820 - acc: 0.9567 - val_loss: 0.4331 - val_acc: 0.8642
Epoch 15/20
25000/25000 [==============================] - 2s 66us/step - loss: 0.1816 - acc: 0.9574 - val_loss: 0.4568 - val_acc: 0.8566
Epoch 16/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.1757 - acc: 0.9596 - val_loss: 0.4463 - val_acc: 0.8643
Epoch 17/20
25000/25000 [==============================] - 2s 68us/step - loss: 0.1717 - acc: 0.9613 - val_loss: 0.4222 - val_acc: 0.8696
Epoch 18/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.1665 - acc: 0.9637 - val_loss: 0.4374 - val_acc: 0.8672
Epoch 19/20
25000/25000 [==============================] - 2s 62us/step - loss: 0.1648 - acc: 0.9642 - val_loss: 0.4623 - val_acc: 0.8594
Epoch 20/20
25000/25000 [==============================] - 2s 68us/step - loss: 0.1616 - acc: 0.9667 - val_loss: 0.4412 - val_acc: 0.8665
l2_model_val_loss = l2_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, l2_model_val_loss, 'bo', label='L2-regularized model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
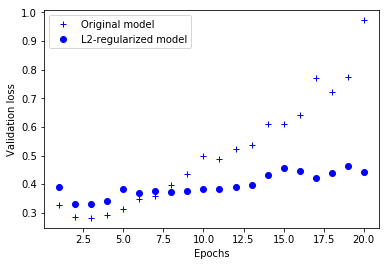
그림 4-7. 검증 손실에 대한 L2 가중치 규제의 효과
여기서 볼 수 있듯이 두 모델이 동일한 파라미터 수를 가지고 있더라도 L2 규제를 사용한 모델(점)이 기본 모델(덧셈 기호)보다 훨씬 더 과대적합에 잘 견디고 있습니다.
케라스에서 L2 규제 대신에 다음과 같은 가중치 규제 중 하나를 사용할 수 있습니다:
from keras import regularizers
# L1 규제
regularizers.l1(0.001)
# L1과 L2 규제 병행
regularizers.l1_l2(l1=0.001, l2=0.001)
l1(0.0001) 모델과 비교
l1_model = models.Sequential()
l1_model.add(layers.Dense(16, kernel_regularizer=regularizers.l1(0.0001),
activation='relu', input_shape=(10000,)))
l1_model.add(layers.Dense(16, kernel_regularizer=regularizers.l1(0.0001),
activation='relu'))
l1_model.add(layers.Dense(1, activation='sigmoid'))
l1_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
l1_model_hist = l1_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 2s 72us/step - loss: 0.5502 - acc: 0.8246 - val_loss: 0.4253 - val_acc: 0.8731
Epoch 2/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.3636 - acc: 0.8954 - val_loss: 0.3726 - val_acc: 0.8845
Epoch 3/20
25000/25000 [==============================] - 2s 62us/step - loss: 0.3272 - acc: 0.9053 - val_loss: 0.3768 - val_acc: 0.8760
Epoch 4/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.3062 - acc: 0.9136 - val_loss: 0.3538 - val_acc: 0.8876
Epoch 5/20
25000/25000 [==============================] - 2s 64us/step - loss: 0.2960 - acc: 0.9168 - val_loss: 0.3572 - val_acc: 0.8858
Epoch 6/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2885 - acc: 0.9204 - val_loss: 0.3910 - val_acc: 0.8732
Epoch 7/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2795 - acc: 0.9244 - val_loss: 0.3763 - val_acc: 0.8805
Epoch 8/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2768 - acc: 0.9260 - val_loss: 0.3679 - val_acc: 0.8845
Epoch 9/20
25000/25000 [==============================] - 2s 62us/step - loss: 0.2742 - acc: 0.9264 - val_loss: 0.3745 - val_acc: 0.8839
Epoch 10/20
25000/25000 [==============================] - 2s 62us/step - loss: 0.2659 - acc: 0.9307 - val_loss: 0.3783 - val_acc: 0.8809
Epoch 11/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2603 - acc: 0.9330 - val_loss: 0.3844 - val_acc: 0.8816
Epoch 12/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2636 - acc: 0.9314 - val_loss: 0.3998 - val_acc: 0.8741
Epoch 13/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2557 - acc: 0.9351 - val_loss: 0.4169 - val_acc: 0.8708
Epoch 14/20
25000/25000 [==============================] - 2s 62us/step - loss: 0.2509 - acc: 0.9382 - val_loss: 0.4548 - val_acc: 0.8604
Epoch 15/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2483 - acc: 0.9384 - val_loss: 0.4024 - val_acc: 0.8763
Epoch 16/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2402 - acc: 0.9427 - val_loss: 0.4454 - val_acc: 0.8611
Epoch 17/20
25000/25000 [==============================] - 2s 63us/step - loss: 0.2397 - acc: 0.9434 - val_loss: 0.4198 - val_acc: 0.8718
Epoch 18/20
25000/25000 [==============================] - 2s 61us/step - loss: 0.2328 - acc: 0.9454 - val_loss: 0.4076 - val_acc: 0.8759
Epoch 19/20
25000/25000 [==============================] - 2s 64us/step - loss: 0.2272 - acc: 0.9495 - val_loss: 0.4145 - val_acc: 0.8746
Epoch 20/20
25000/25000 [==============================] - 2s 62us/step - loss: 0.2222 - acc: 0.9493 - val_loss: 0.4149 - val_acc: 0.8752
l1_model_val_loss = l1_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, l1_model_val_loss, 'bo', label='L1-regularized model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
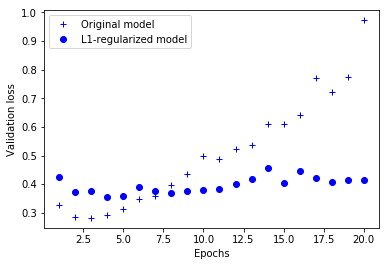
l1_l2(l1=0.0001, l2=0.0001)모델과 비교
l1l2_model = models.Sequential()
l1l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l1_l2(l1=0.0001, l2=0.0001),
activation='relu', input_shape=(10000,)))
l1l2_model.add(layers.Dense(16, kernel_regularizer=regularizers.l1_l2(l1=0.0001, l2=0.0001),
activation='relu'))
l1l2_model.add(layers.Dense(1, activation='sigmoid'))
l1l2_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
l1l2_model_hist = l1l2_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 2s 92us/step - loss: 0.5541 - acc: 0.8168 - val_loss: 0.4444 - val_acc: 0.8563
Epoch 2/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3722 - acc: 0.8947 - val_loss: 0.3823 - val_acc: 0.8836
Epoch 3/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3349 - acc: 0.9060 - val_loss: 0.3800 - val_acc: 0.8812
Epoch 4/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3230 - acc: 0.9090 - val_loss: 0.3645 - val_acc: 0.8873
Epoch 5/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3103 - acc: 0.9145 - val_loss: 0.3826 - val_acc: 0.8787
Epoch 6/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3044 - acc: 0.9175 - val_loss: 0.3736 - val_acc: 0.8849
Epoch 7/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2967 - acc: 0.9188 - val_loss: 0.3726 - val_acc: 0.8846
Epoch 8/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2963 - acc: 0.9190 - val_loss: 0.3773 - val_acc: 0.8839
Epoch 9/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2882 - acc: 0.9245 - val_loss: 0.3889 - val_acc: 0.8806
Epoch 10/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2818 - acc: 0.9268 - val_loss: 0.3815 - val_acc: 0.8831
Epoch 11/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2789 - acc: 0.9266 - val_loss: 0.3825 - val_acc: 0.8822
Epoch 12/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2749 - acc: 0.9294 - val_loss: 0.3872 - val_acc: 0.8812
Epoch 13/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2696 - acc: 0.9312 - val_loss: 0.3976 - val_acc: 0.8744
Epoch 14/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2610 - acc: 0.9350 - val_loss: 0.3933 - val_acc: 0.8780
Epoch 15/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2579 - acc: 0.9371 - val_loss: 0.4073 - val_acc: 0.8743
Epoch 16/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2505 - acc: 0.9389 - val_loss: 0.4054 - val_acc: 0.8758
Epoch 17/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2478 - acc: 0.9396 - val_loss: 0.4036 - val_acc: 0.8767
Epoch 18/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2420 - acc: 0.9426 - val_loss: 0.4476 - val_acc: 0.8634
Epoch 19/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2408 - acc: 0.9409 - val_loss: 0.4184 - val_acc: 0.8746
Epoch 20/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2369 - acc: 0.9448 - val_loss: 0.4186 - val_acc: 0.8748
l1l2_model_val_loss = l1l2_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, l1l2_model_val_loss, 'bo', label='L1,L2-regularized model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
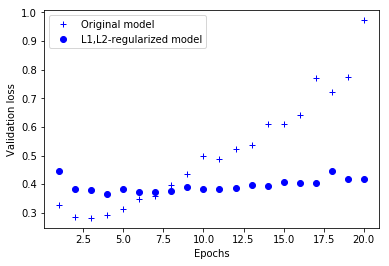
4.4.3 드롭아웃 추가
드롭아웃(dropout)은 토론토 대학의 제프리 힌튼과 그의 학생들이 개발했습니다. 신경망을 위해 사용되는 규제 기법 중에서 가장 효과적이고 널리 사용되는 방법 중 하나입니다. 네트워크 층에 드롭아웃을 적용하면 훈련하는 동안 무작위로 층의 일부 출력 특성을 제외시킵니다(0으로 만듭니다). 한 층이 정상적으로 훈련하는 동안에는 어떤 입력 샘플에 대해 [0.2, 0.5, 1.3, 0.8, 1.1] 벡터를 출력한다고 가정합시다. 드롭아웃을 적용하면 이 벡터의 일부가 무작위로 0으로 바뀝니다. 예를 들어 [0, 0.5, 1.3, 0, 1.1]이 됩니다. 드롭아웃 비율은 0이 될 특성의 비율입니다. 보통 0.2에서 0.5 사이로 지정됩니다. 테스트 단계에서는 어떤 유닛도 드롭아웃되지 않습니다. 그 대신에 층의 출력을 드롭아웃 비율에 비례하여 줄여 줍니다. 훈련할 때보다 더 많은 유닛이 활성화되기 때문입니다.
크기가 (batch_size, features)인 한 층의 출력을 담고 있는 넘파이 행렬을 생각해 보겠습니다. 훈련할 때는 이 행렬 값의 일부가 랜덤하게 0이 됩니다.
# 훈련할 때 유닛의 출력 중 50%를 버립니다
layer_output *= np.random.randint(0, high=2, size=layer_output.shape)
테스트할 때는 드롭아웃 비율로 출력을 낮추어 주어야 합니다. 여기에서는 0.5배만큼 스케일을 조정했습니다(앞에서 절반의 유닛을 드롭아웃했으므로).
# 테스트 단계
layer_output *= 0.5
훈련 단계에 이 두 연산을 포함시켜 테스트 단계에는 출력을 그대로 두도록 구현할 수 있습니다. 실제로 종종 이런 방식으로 구현합니다(그림 4-8 참고).7
# 훈련 단계
layer_output *= np.randint(0, high=2, size=layer_output.shape)
# 여기에서 스케일을 낮추는 대신 높입니다
layer_output /= 0.5

▲ 그림 4-8 훈련 단계에서 활성화 함수의 출력 행렬에 적용된 드롭아웃으로, 훈련할 때 스케일을 높여 주고 테스트 단계에서는 활성화 함수의 출력을 그대로 사용한다
이 기법이 이상하고 무계획적으로 보일 수 있습니다. 왜 드롭아웃이 과대적합을 줄이는 데 도움이 될까요? 힌튼은 은행에서 사용하는 부정 방지 메커니즘에서 착안했다고 합니다. 그의 말을 빌리면 “은행에 갔을 때 행원들이 계속 바뀌길래 왜 그런지를 물었습니다. 자신들도 이유는 모르지만 자주 업무가 바뀐다고 했습니다. 나는 은행에서 부정 행위를 하려면 직원들 사이의 유대가 필요하기 때문이라고 판단했습니다. 각 샘플에 대해 뉴런의 일부를 무작위하게 제거하면 뉴런의 부정한 협업을 방지하고 결국 과대적합을 감소시킨다는 것을 깨달았습니다.”8
핵심 아이디어는 층의 출력 값에 노이즈를 추가하여 중요하지 않은 우연한 패턴(힌튼이 이야기한 부정한 협업)을 깨뜨리는 것입니다. 노이즈가 없다면 네트워크가 이 패턴을 기억하기 시작할 것입니다.
케라스에서는 층의 출력 바로 뒤에 Dropout 층을 추가하여 네트워크에 드롭아웃을 적용할 수 있습니다:
model.add(layers.Dropout(0.5))
IMDB 네트워크에 두 개의 Dropout 층을 추가하고 과대적합을 얼마나 줄여주는지 확인해 보겠습니다:
# 코드 4-8 IMDB 네트워크에 드롭아웃 추가하기
dpt_model = models.Sequential()
dpt_model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
dpt_model.add(layers.Dropout(0.5))
dpt_model.add(layers.Dense(16, activation='relu'))
dpt_model.add(layers.Dropout(0.5))
dpt_model.add(layers.Dense(1, activation='sigmoid'))
dpt_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
dpt_model_hist = dpt_model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))
Train on 25000 samples, validate on 25000 samples
Epoch 1/20
25000/25000 [==============================] - 2s 94us/step - loss: 0.5963 - acc: 0.6720 - val_loss: 0.4509 - val_acc: 0.8563
Epoch 2/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.4414 - acc: 0.8197 - val_loss: 0.3414 - val_acc: 0.8836
Epoch 3/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.3557 - acc: 0.8696 - val_loss: 0.2940 - val_acc: 0.8886
Epoch 4/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2968 - acc: 0.9008 - val_loss: 0.2823 - val_acc: 0.8896
Epoch 5/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2575 - acc: 0.9134 - val_loss: 0.2827 - val_acc: 0.8896
Epoch 6/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2298 - acc: 0.9246 - val_loss: 0.2863 - val_acc: 0.8879
Epoch 7/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.2073 - acc: 0.9342 - val_loss: 0.3196 - val_acc: 0.8852
Epoch 8/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1864 - acc: 0.9401 - val_loss: 0.3235 - val_acc: 0.8854
Epoch 9/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1702 - acc: 0.9457 - val_loss: 0.3446 - val_acc: 0.8832
Epoch 10/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1566 - acc: 0.9507 - val_loss: 0.3812 - val_acc: 0.8823
Epoch 11/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1478 - acc: 0.9541 - val_loss: 0.3830 - val_acc: 0.8811
Epoch 12/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1396 - acc: 0.9563 - val_loss: 0.4123 - val_acc: 0.8812
Epoch 13/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1346 - acc: 0.9596 - val_loss: 0.4472 - val_acc: 0.8770
Epoch 14/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1218 - acc: 0.9621 - val_loss: 0.4721 - val_acc: 0.8803
Epoch 15/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1242 - acc: 0.9618 - val_loss: 0.4887 - val_acc: 0.8773
Epoch 16/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1169 - acc: 0.9643 - val_loss: 0.4918 - val_acc: 0.8766
Epoch 17/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1149 - acc: 0.9656 - val_loss: 0.4986 - val_acc: 0.8719
Epoch 18/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1098 - acc: 0.9677 - val_loss: 0.5318 - val_acc: 0.8737
Epoch 19/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1038 - acc: 0.9685 - val_loss: 0.5627 - val_acc: 0.8746
Epoch 20/20
25000/25000 [==============================] - 2s 82us/step - loss: 0.1042 - acc: 0.9691 - val_loss: 0.5747 - val_acc: 0.8742
결과 그래프를 그려 보죠.
dpt_model_val_loss = dpt_model_hist.history['val_loss']
plt.plot(epochs, original_val_loss, 'b+', label='Original model')
plt.plot(epochs, dpt_model_val_loss, 'bo', label='Dropout-regularized model')
plt.xlabel('Epochs')
plt.ylabel('Validation loss')
plt.legend()
plt.show()
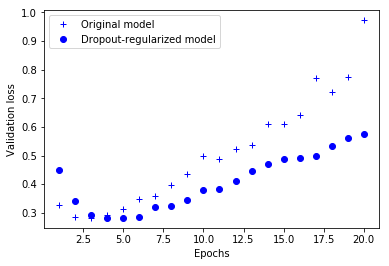
그림 4-9 검증 손실에 대한 드롭아웃의 효과
여기에서도 기본 네트워크보다 확실히 향상되었습니다.
정리하면 신경망에서 과대적합을 방지하기 위해 가장 널리 사용하는 방법은 다음과 같습니다.
- 훈련 데이터를 더 모읍니다.
- 네트워크의 용량을 감소시킵니다.
- 가중치 규제를 추가합니다.
- 드롭아웃을 추가합니다.
-
이 절에서 사용된 영화 리뷰 데이터의 전처리 과정은 3장과 동일합니다. 책에는 전처리 과정, 모델 훈련, 그래프 생성 코드 등이 빠져 있습니다. 전체 코드는 주피터 노트북을 참고하세요. ↩
-
L2 노름은 유클리디안 노름(Euclidean norm)이라고도 부릅니다. 가중치의 파라미터를 모두 제곱하여 더한 후 이 값의 제곱근을 구합니다. L2 규제에서 추가되는 비용은 정확히는 L2 노름의 제곱입니다. 하지만 여기처럼 종종 그냥 L2 노름이라고 이야기하는 경우가 많습니다. ↩
-
regularizers.l2()함수는regularizers.L1L2클래스의 객체를 반환하는 간단한 함수입니다. 이 함수 대신regularizers.L1L2(l2=0.001)을 사용해도 됩니다. ↩ -
손실 함수에 추가로 더해지는 규제를 종종 페널티라고도 부릅니다. ↩
-
L2 규제는 가중치 값을 작게 만들지만 완전히 0이 되지는 않습니다. L1 규제는 일부 가중치 값을 완전히 0으로 만들 수 있습니다. L1 규제와 L2 규제를 함께 쓰는 방식을 엘라스틱넷(ElasticNet)이라고도 부릅니다. l1(), l2(), l1_l2() 함수의 매개변수 기본값은 모두 0.01입니다. l1()과 l1_l2() 함수를 사용했을 때 효과는 번역서 깃허브의 주피터 노트북을 참고하세요. ↩
-
randint(0, high=2)는 0(포함)~2(미포함) 사이의 정수를 반환합니다. 즉 0 또는 1이 반환됩니다. 앞서 layer_output이란 배열을 만들지 않았습니다. 이 코드와 이어지는 2개의 코드는 작동 원리를 설명하기 위한 예시입니다. ↩
-
케라스는 백엔드 엔진의 드롭아웃 연산을 사용합니다. 대표적으로 텐서플로가 이와 같이 훈련 단계의 출력 값에
(1 - dropout_rate)을 나누어 드롭아웃을 구현합니다. 테스트 단계에서 가중치에(1 - dropout_rate)을 곱하는 것과 완전히 동일하지는 않지만 잘 작동합니다. ↩ -
레딧(Reddit)의 글타래를 참고하세요. “AMA: We are the Google Brain team. We’d love to answer your questions about machine learning,” http://mng.bz/XrsS. ↩
댓글남기기