5.2 소규모 데이터셋에서 밑바닥부터 컨브넷 사용하기
import keras
keras.__version__
Using TensorFlow backend.
'2.3.1'
수백 개에서 수만 개 사이의 적은 데이터를 사용하여 이미지 분류 모델을 훈련하는 일은 흔한 경우입니다. 여러분이 전문적인 컴퓨터 비전 작업을 한다면 실제로 이런 상황을 마주치게 될 가능성이 높습니다.
여기서는 실용적인 예제로 4,000개의 강아지와 고양이 사진(2,000개는 강아지, 2,000개는 고양이)으로 구성된 데이터셋에서 강아지와 고양이 이미지를 분류해 보겠습니다. 훈련을 위해 2,000개의 사진을 사용하고 검증과 테스트에 각각 1,000개의 사진을 사용합니다.
이 문제를 해결하기 위해 아래의 전략들을 살펴보겠습니다.
이 절에서는 보유한 소규모 데이터셋을 사용하여 처음부터 새로운 모델을 훈련하는 것을 살펴보겠습니다. 2,000개의 훈련 샘플에서 작은 컨브넷을 어떤 규제 방법도 사용하지 않고 훈련하여 기준이 되는 기본 성능을 만듭니다. 이 방법은 71%의 분류 정확도를 달성할 것입니다. 또한 이 방법의 주요 이슈는 과대적합이 될 것입니다. 다음으로 컴퓨터 비전에서 과대적합을 줄이기 위한 강력한 방법인 데이터 증식(data augmentation)을 소개하겠습니다. 데이터 증식을 통해 네트워크의 성능을 82% 정확도로 향상시킬 것입니다.
다음 절에서는 작은 데이터셋에 딥러닝을 적용하기 위한 핵심적인 기술 두 가지를 살펴보겠습니다. 사전 훈련된 네트워크로 특성을 추출하는 것(90%의 정확도를 얻게 됩니다)과 사전 훈련된 네트워크를 세밀하게 튜닝하는 것입니다(최종 모델은 92% 정확도를 얻을 것입니다). 이런 세 가지 전략(처음부터 작은 모델을 훈련하기, 사전 훈련된 모델을 사용하여 특성 추출하기, 사전 훈련된 모델을 세밀하게 튜닝하기)은 작은 데이터셋에서 이미지 분류 문제를 수행할 때 여러분의 도구 상자에 포함되어 있어야 합니다.
5.2.1 작은 데이터셋 문제에서 딥러닝의 타당성
딥러닝의 근본적인 특징은 훈련 데이터에서 특성 공학의 수작업 없이 흥미로운 특성을 찾을 수 있는 것입니다. 이는 훈련 샘플이 많아야만 가능합니다. 입력 샘플이 이미지처럼 매우 고차원인 문제에서는 특히 그렇습니다.
하지만 많은 샘플이 의미하는 것은 상대적입니다. 우선 훈련하려는 네트워크의 크기와 깊이에 상대적입니다. 복잡한 문제를 푸는 컨브넷을 수십 개의 샘플만 사용해서 훈련하는 것은 불가능합니다. 하지만 모델이 작고 규제가 잘 되어 있으며 간단한 작업이라면 수백 개의 샘플로도 충분할 수 있습니다.
컨브넷은 지역적이고 평행 이동으로 변하지 않는 특성을 학습하기 때문에 지각에 관한 문제에서 매우 효율적으로 데이터를 사용합니다. 매우 작은 이미지 데이터셋에서 어떤 종류의 특성 공학을 사용하지 않고 컨브넷을 처음부터 훈련해도 납득할 만한 결과를 만들 수 있습니다. 이 절에서 실제로 이런 결과를 보게 될 것입니다.
또한, 딥러닝 모델은 태생적으로 매우 다목적입니다. 말하자면 대규모 데이터셋에서 훈련시킨 이미지 분류 모델이나 스피치-투-텍스트(speech-to-text) 모델을 조금만 변경해서 완전히 다른 문제에 재사용할 수 있습니다. 특히 컴퓨터 비전에서는 (보통 ImageNet 데이터셋에서 훈련된) 사전 훈련된 모델들이 다운로드받을 수 있도록 많이 공개되어 있어서 매우 적은 데이터에서 강력한 비전 모델을 만드는 데 사용할 수 있습니다. 이는 다음 절에서 살펴 보겠습니다.
먼저 데이터를 구하는 것부터 시작해 보죠.
5.2.2 데이터 내려받기
여기서 사용할 강아지 vs. 고양이 데이터셋(Dogs vs. Cats dataset)은 케라스에 포함되어 있지 않습니다. 컨브넷이 주류가 되기 전인 2013년 후반에 캐글에서 컴퓨터 비전 경연 대회의 일환으로 이 데이터셋을 만들었습니다. 원본 데이터셋을 https://www.kaggle.com/c/dogs-vs-cats/data에서 내려받을 수 있습니다.1
이 사진들은 중간 정도의 해상도를 가진 컬러 JPEG 파일입니다.

그림 5-8. 강아지 vs. 고양이 데이터셋의 샘플로 이 샘플들은 원본 크기 그대로이며, 샘플들은 사이즈와 모습 등이 제각각이다
2013년 강아지 vs. 고양이 캐글 경연은 컨브넷을 사용한 참가자가 우승하였습니다. 최고 성능은 95%의 정확도를 달성했습니다. 이 예제를 가지고 (다음 절에서) 참가자들이 사용했던 데이터의 10%보다 적은 양으로 모델을 훈련하고도 이와 아주 근접한 정확도를 달성해 보겠습니다.
이 데이터셋은 25,000개의 강아지와 고양이 이미지(클래스마다 12,500개)를 담고 있고 (압축해서) 543MB 크기입니다. 다운로드하고 압축을 해제한 후 세 개의 서브셋이 들어 있는 새로운 데이터셋을 만들 것입니다. 클래스마다 1,000개의 샘플로 이루어진 훈련 세트, 클래스마다 500개의 샘플로 이루어진 검증 세트, 클래스마다 500개의 샘플로 이루어진 테스트 세트입니다.2
다음은 이를 처리하는 코드입니다.
# 코드 5-4. 훈련, 검증, 테스트 폴더로 이미지 복사하기
import os, shutil
# 원본 데이터셋을 압축 해제한 디렉터리 경로
original_dataset_dir = './datasets/cats_and_dogs/train'
# 소규모 데이터셋을 저장할 디렉터리
base_dir = './datasets/cats_and_dogs_small'
if os.path.exists(base_dir): # 반복적인 실행을 위해 디렉토리를 삭제합니다.
shutil.rmtree(base_dir) # 이 코드는 책에 포함되어 있지 않습니다.
os.mkdir(base_dir)
# 훈련, 검증, 테스트 분할을 위한 디렉터리
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 훈련용 고양이 사진 디렉터리
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 훈련용 강아지 사진 디렉터리
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 검증용 고양이 사진 디렉터리
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 검증용 강아지 사진 디렉터리
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 테스트용 고양이 사진 디렉터리
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# 테스트용 강아지 사진 디렉터리
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 처음 1,000개의 고양이 이미지를 train_cats_dir에 복사합니다
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 고양이 이미지를 validation_cats_dir에 복사합니다
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 고양이 이미지를 test_cats_dir에 복사합니다
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 처음 1,000개의 강아지 이미지를 train_dogs_dir에 복사합니다
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 강아지 이미지를 validation_dogs_dir에 복사합니다
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 다음 500개 강아지 이미지를 test_dogs_dir에 복사합니다
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
복사가 잘 되었는지 확인하기 위해 각 분할(훈련/검증/테스트)에 들어 있는 사진의 개수를 카운트해 보겠습니다.
print('훈련용 고양이 이미지 전체 개수:', len(os.listdir(train_cats_dir)))
훈련용 고양이 이미지 전체 개수: 1000
print('훈련용 강아지 이미지 전체 개수:', len(os.listdir(train_dogs_dir)))
훈련용 강아지 이미지 전체 개수: 1000
print('검증용 고양이 이미지 전체 개수:', len(os.listdir(validation_cats_dir)))
검증용 고양이 이미지 전체 개수: 500
print('검증용 강아지 이미지 전체 개수:', len(os.listdir(validation_dogs_dir)))
검증용 강아지 이미지 전체 개수: 500
print('테스트용 고양이 이미지 전체 개수:', len(os.listdir(test_cats_dir)))
테스트용 고양이 이미지 전체 개수: 500
print('테스트용 강아지 이미지 전체 개수:', len(os.listdir(test_dogs_dir)))
테스트용 강아지 이미지 전체 개수: 500
이제 2,000개의 훈련 이미지, 1,000개의 검증 이미지, 1,000개의 테스트 이미지가 준비되었습니다. 분할된 각 데이터는 클래마다 동일한 개수의 샘플을 포함합니다. 균형잡힌 이진 분류 문제이므로 정확도를 사용해 성공을 측정하겠습니다.
5.2.3 네트워크 구성하기
MNIST 예제와 비슷하지만 이번 예제는 이미지가 크고 복잡한 문제이기 때문에 네트워크를 좀 더 크게 만들겠습니다. Conv2D + MaxPooling2D 단계를 하나 더 추가합니다. 이렇게 하면 150×150 크기(임의로 선택한 것입니다)의 입력으로 시작해서 Flatten 층 이전에 7×7 크기의 특성 맵으로 줄어듭니다.
Note
특성 맵의 깊이는 네트워크에서 점진적으로 증가하지만(32에서 128까지), 특성 맵의 크기는 감소합니다(150×150에서 7×7까지). 이는 거의 모든 컨브넷에서 볼 수 있는 전형적인 패턴입니다.
이진 분류 문제이므로 네트워크는 하나의 유닛(크기가 1인 Dense 층)과 sigmoid 활성화 함수로 끝납니다. 이 유닛은 한 클래스에 대한 확률을 인코딩할 것입니다. 3
# 코드 5-5. 강아지 vs. 고양이 분류를 위한 소규모 컨브넷 만들기
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
층들을 거치면서 특성 맵의 차원이 어떻게 변하는지 살펴보겠습니다.
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
컴파일 단계에서 이전과 같이 RMSprop 옵티마이저를 선택하겠습니다. 네트워크의 마지막이 하나의 시그모이드 유닛이기 때문에 이진 크로스엔트로피(binary crossentropy)를 손실로 사용합니다(4.5절에서 다양한 경우에 사용할 수 있는 손실 함수 목록을 볼 수 있습니다).
# 코드 5-6. 모델의 훈련 설정하기
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
5.2.4 데이터 전처리
데이터는 네트워크에 주입되기 전에 부동 소수 타입의 텐서로 적절하게 전처리되어 있어야 합니다. 지금은 데이터가 JPEG 파일로 되어 있으므로 네트워크에 주입하려면 대략 다음 과정을 따릅니다.
- 사진 파일을 읽습니다.
- JPEG 콘텐츠를 RGB 픽셀 값으로 디코딩합니다.
- 그다음 부동 소수 타입의 텐서로 변환합니다.
- 픽셀 값(0에서 255 사이)의 스케일을 [0, 1] 사이로 조정합니다(신경망은 작은 입력 값을 선호합니다).
케라스는 이런 단계를 자동으로 처리하는 유틸리티가 있습니다. 또 케라스에는 keras.preprocessing.image에 이미지 처리를 위한 헬퍼 도구들도 있습니다.4 특히 ImageDataGenerator 클래스는 디스크에 있는 이미지 파일을 전처리된 배치 텐서로 자동으로 바꾸어 주는 파이썬 제너레이터(generator)를 만들어 줍니다. 이 클래스를 사용해 보겠습니다.
# 코드 5-7. ImageDataGenerator를 사용하여 디렉터리에서 이미지 읽기
from keras.preprocessing.image import ImageDataGenerator
# 모든 이미지를 1/255로 스케일을 조정합니다
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=20,
# binary_crossentropy 손실을 사용하기 때문에 이진 레이블이 필요합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Note 파이썬 제너레이터 이해하기
파이썬 제너레이터(generator)는 반복자(iterator)처럼 작동하는 객체로 for … in 연산자에 사용할 수 있습니다. 제너레이터는 yield6 연산자를 사용하여 만듭니다.
다음은 정수를 반환하는 제너레이터의 예입니다.
def generator():
i = 0
while True:
i += 1
yield i
for item in generator():
print(item)
if item > 4:
break
다음과 같이 출력됩니다.
1
2
3
4
5
이 제너레이터의 출력 하나를 살펴보죠. 이 출력은 150 × 150 RGB 이미지의 배치((20, 150, 150, 3) 크기)와 이진 레이블의 배치((20,) 크기)입니다. 각 배치에는 20개의 샘플(배치 크기)이 있습니다. 제너레이터는 이 배치를 무한정 만들어 냅니다. 타깃 폴더에 있는 이미지를 끝없이 반복합니다. 따라서 반복 루프안의 어디에선가 break 문을 사용해야 합니다.
for data_batch, labels_batch in train_generator:
print('배치 데이터 크기:', data_batch.shape)
print('배치 레이블 크기:', labels_batch.shape)
break
배치 데이터 크기: (20, 150, 150, 3)
배치 레이블 크기: (20,)
제너레이터를 사용한 데이터에 모델을 훈련시켜 보겠습니다. fit_generator 메서드는 fit 메서드와 동일하되 데이터 제너레이터를 사용할 수 있습니다. 이 메서드는 첫 번째 매개변수로 입력과 타깃의 배치를 끝없이 반환하는 파이썬 제너레이터를 기대합니다. 데이터가 끝없이 생성되기 때문에 케라스 모델에 하나의 에포크를 정의하기 위해 제너레이터로부터 얼마나 많은 샘플을 뽑을 것인지 알려 주어야 합니다. steps_per_epoch 매개변수에서 이를 설정합니다. 제너레이터로부터 steps_per_epoch 개의 배치만큼 뽑은 다음, 즉 steps_per_epoch 횟수만큼 경사 하강법 단계를 실행한 다음에 훈련 프로세스는 다음 에포크로 넘어갑니다. 여기서는 20개의 샘플이 하나의 배치이므로 2,000개의 샘플을 모두 처리할 때까지 100개의 배치를 뽑을 것입니다.
fit_generator를 사용할 때 fit 메서드와 마찬가지로 validation_data 매개변수를 전달할 수 있습니다. 이 매개변수에는 데이터 제너레이터도 가능하지만 넘파이 배열의 튜플도 가능합니다. validation_data로 제너레이터를 전달하면 검증 데이터의 배치를 끝없이 반환합니다. 따라서 검증 데이터 제너레이터에서 얼마나 많은 배치를 추출하여 평가할지 validation_steps 매개변수에 지정해야 합니다.7
# 코드 5-8. 배치 제너레이터를 사용하여 모델 훈련하기
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/30
100/100 [==============================] - 15s 152ms/step - loss: 0.6871 - acc: 0.5345 - val_loss: 0.6450 - val_acc: 0.6020
Epoch 2/30
100/100 [==============================] - 5s 55ms/step - loss: 0.6456 - acc: 0.6140 - val_loss: 0.6959 - val_acc: 0.5860
Epoch 3/30
100/100 [==============================] - 5s 55ms/step - loss: 0.5945 - acc: 0.6710 - val_loss: 0.5580 - val_acc: 0.6360
Epoch 4/30
100/100 [==============================] - 5s 55ms/step - loss: 0.5618 - acc: 0.7185 - val_loss: 0.4533 - val_acc: 0.6740
Epoch 5/30
100/100 [==============================] - 5s 55ms/step - loss: 0.5345 - acc: 0.7365 - val_loss: 0.7350 - val_acc: 0.6520
Epoch 6/30
100/100 [==============================] - 5s 54ms/step - loss: 0.5077 - acc: 0.7490 - val_loss: 0.5294 - val_acc: 0.6810
Epoch 7/30
100/100 [==============================] - 5s 54ms/step - loss: 0.4810 - acc: 0.7675 - val_loss: 0.4694 - val_acc: 0.6750
Epoch 8/30
100/100 [==============================] - 5s 55ms/step - loss: 0.4563 - acc: 0.7905 - val_loss: 0.6499 - val_acc: 0.7020
Epoch 9/30
100/100 [==============================] - 5s 55ms/step - loss: 0.4334 - acc: 0.8010 - val_loss: 0.4263 - val_acc: 0.7100
Epoch 10/30
100/100 [==============================] - 5s 55ms/step - loss: 0.4029 - acc: 0.8235 - val_loss: 0.3879 - val_acc: 0.7110
Epoch 11/30
100/100 [==============================] - 6s 56ms/step - loss: 0.3771 - acc: 0.8370 - val_loss: 0.3005 - val_acc: 0.7140
Epoch 12/30
100/100 [==============================] - 5s 55ms/step - loss: 0.3538 - acc: 0.8445 - val_loss: 0.5371 - val_acc: 0.7130
Epoch 13/30
100/100 [==============================] - 5s 55ms/step - loss: 0.3356 - acc: 0.8560 - val_loss: 0.7710 - val_acc: 0.7160
Epoch 14/30
100/100 [==============================] - 6s 55ms/step - loss: 0.3077 - acc: 0.8690 - val_loss: 0.5434 - val_acc: 0.7150
Epoch 15/30
100/100 [==============================] - 6s 55ms/step - loss: 0.2844 - acc: 0.8810 - val_loss: 0.6547 - val_acc: 0.7090
Epoch 16/30
100/100 [==============================] - 6s 55ms/step - loss: 0.2568 - acc: 0.9015 - val_loss: 0.4248 - val_acc: 0.7200
Epoch 17/30
100/100 [==============================] - 8s 82ms/step - loss: 0.2437 - acc: 0.9080 - val_loss: 0.7184 - val_acc: 0.7230
Epoch 18/30
100/100 [==============================] - 11s 111ms/step - loss: 0.2196 - acc: 0.9130 - val_loss: 0.9215 - val_acc: 0.7250
Epoch 19/30
100/100 [==============================] - 5s 54ms/step - loss: 0.1942 - acc: 0.9220 - val_loss: 1.5035 - val_acc: 0.7080
Epoch 20/30
100/100 [==============================] - 5s 55ms/step - loss: 0.1816 - acc: 0.9290 - val_loss: 0.9347 - val_acc: 0.7330
Epoch 21/30
100/100 [==============================] - 6s 55ms/step - loss: 0.1576 - acc: 0.9460 - val_loss: 1.1087 - val_acc: 0.7150
Epoch 22/30
100/100 [==============================] - 6s 56ms/step - loss: 0.1371 - acc: 0.9545 - val_loss: 0.8448 - val_acc: 0.7140
Epoch 23/30
100/100 [==============================] - 5s 55ms/step - loss: 0.1290 - acc: 0.9590 - val_loss: 0.6198 - val_acc: 0.7180
Epoch 24/30
100/100 [==============================] - 5s 55ms/step - loss: 0.1093 - acc: 0.9620 - val_loss: 0.5779 - val_acc: 0.7140
Epoch 25/30
100/100 [==============================] - 5s 55ms/step - loss: 0.0943 - acc: 0.9725 - val_loss: 0.7507 - val_acc: 0.7060
Epoch 26/30
100/100 [==============================] - 5s 55ms/step - loss: 0.0876 - acc: 0.9695 - val_loss: 0.5523 - val_acc: 0.7150
Epoch 27/30
100/100 [==============================] - 5s 55ms/step - loss: 0.0699 - acc: 0.9815 - val_loss: 0.9434 - val_acc: 0.7080
Epoch 28/30
100/100 [==============================] - 5s 55ms/step - loss: 0.0597 - acc: 0.9855 - val_loss: 0.3960 - val_acc: 0.6960
Epoch 29/30
100/100 [==============================] - 5s 54ms/step - loss: 0.0545 - acc: 0.9865 - val_loss: 0.3795 - val_acc: 0.7230
Epoch 30/30
100/100 [==============================] - 5s 55ms/step - loss: 0.0465 - acc: 0.9875 - val_loss: 0.8080 - val_acc: 0.7140
훈련이 끝나면 항상 모델을 저장하는 것이 좋은 습관입니다.
# 코드 5-9. 모델 저장하기
model.save('cats_and_dogs_small_1.h5')
훈련 데이터와 검증 데이터에 대한 모델의 손실과 정확도를 그래프로 나타내 보겠습니다(그림 5-9와 그림 5-10 참고).
# 코드 5-10. 훈련의 정확도와 손실 그래프 그리기
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
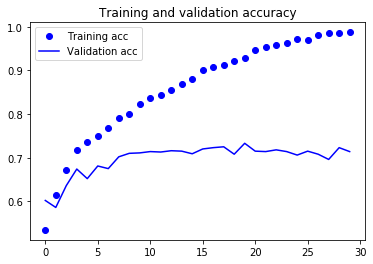
그림 5-9. 훈련 정확도와 검증 정확도
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
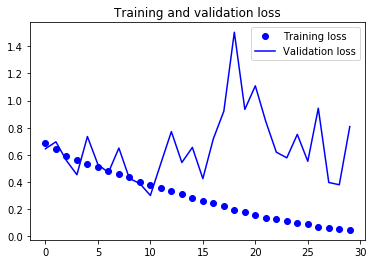
그림 5-10. 훈련 손실과 검증 손실
이 그래프는 과대적합의 특성을 보여줍니다. 훈련 정확도 거의 100%에 도달하는 반면 검증 정확도는 70-72%에서 멈추었습니다. 검증 손실은 열번의 에포크만에 최솟값에 다다른 이후에 더 이상 진전되지 않았습니다. 반면 훈련 손실은 거의 0에 도달할 때까지 선형적으로 계속 감소합니다.
비교적 훈련 샘플의 수(2,000개)가 적기 때문에 과대적합이 가장 중요한 문제입니다. 드롭아웃이나 가중치 감소(L2 규제)와 같은 과대적합을 감소시킬 수 있는 여러 가지 기법들을 배웠습니다. 여기에서는 컴퓨터 비전에 특화되어 있어서 딥러닝으로 이미지를 다룰 때 매우 일반적으로 사용되는 새로운 방법인 데이터 증식을 시도해 보겠습니다.
5.2.3 데이터 증식 사용하기
과대적합은 학습할 샘플이 너무 적어 새로운 데이터에 일반화할 수 있는 모델을 훈련시킬 수 없기 때문에 발생합니다. 데이터 증식은 기존의 훈련 샘플로부터 더 많은 훈련 데이터를 생성하는 방법입니다. 이 방법은 그럴듯한 이미지를 생성하도록 여러 가지 랜덤한 변환을 적용하여 샘플을 늘립니다.
케라스에서는 ImageDataGenerator가 읽은 이미지에 여러 종류의 랜덤 변환을 적용하도록 설정할 수 있습니다. 예제를 먼저 만들어 보죠.
# 코드 5-11. ImageDataGenerator를 사용하여 데이터 증식 설정하기
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
매개변수를 살펴 보겠습니다.(자세한 내용은 케라스 문서를 참고하세요).
rotation_range는 랜덤하게 사진을 회전시킬 각도 범위입니다(0-180 사이).8width_shift_range와height_shift_range는 사진을 수평과 수직으로 랜덤하게 평행 이동시킬 범위입니다(전체 넓이와 높이에 대한 비율).9shear_range는 랜덤하게 전단 변환을 적용할 각도 범위입니다.10zoom_range는 랜덤하게 사진을 확대할 범위입니다.11horizontal_flip은 랜덤하게 이미지를 수평으로 뒤집습니다. 수평 대칭을 가정할 수 있을 때 사용합니다(예를 들어, 풍경/인물 사진).12fill_mode는 회전이나 가로/세로 이동으로 인해 새롭게 생성해야 할 픽셀을 채울 전략입니다.13
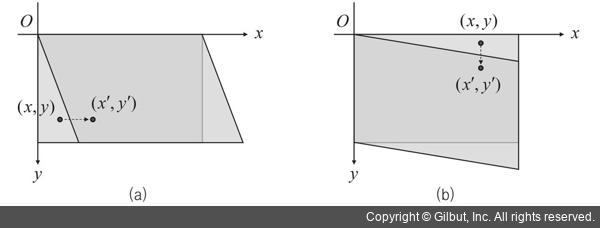
전단 변환
증식된 이미지 샘플을 살펴보죠(그림 5-11 참고).
# 코드 5-12. 랜덤하게 증식된 훈련 이미지 그리기
# 이미지 전처리 유틸리티 모듈
from keras.preprocessing import image
fnames = sorted([os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)])
# 증식할 이미지 선택합니다
img_path = fnames[3]
# 이미지를 읽고 크기를 변경합니다
img = image.load_img(img_path, target_size=(150, 150))
# (150, 150, 3) 크기의 넘파이 배열로 변환합니다
x = image.img_to_array(img)
# (1, 150, 150, 3) 크기로 변환합니다
x = x.reshape((1,) + x.shape)
# flow() 메서드는 랜덤하게 변환된 이미지의 배치를 생성합니다.
# 무한 반복되기 때문에 어느 지점에서 중지해야 합니다!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()




그림 5-11. 랜덤한 데이터 증식으로 생성된 고양이 사진
데이터 증식을 사용하여 늘려도 적은 수의 원본 이미지에서 만들어졌기 때문에 여전히 입력 데이터들 사이에 상호 연관성이 큽니다. 즉, 새로운 정보를 만들어낼 수 없고 단지 기존 정보의 재조합만 가능하기 때문에 완전히 과대적합을 제거하기에 충분하지 않을 수 있습니다. 과대적합을 더 억제하기 위해 완전 연결 분류기15 직전에 Dropout 층을 추가하겠습니다.
# 코드 5-13. 드롭아웃을 포함한 새로운 컨브넷 정의하기
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
데이터 증식과 드롭아웃을 사용하여 이 네트워크를 훈련시켜 봅시다.
# 코드 5-14. 데이터 증식 제너레이터를 사용하여 컨브넷 훈련하기
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지를 150 × 150 크기로 바꿉니다
target_size=(150, 150),
batch_size=32,
# binary_crossentropy 손실을 사용하기 때문에 이진 레이블을 만들어야 합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Epoch 1/100
100/100 [==============================] - 19s 189ms/step - loss: 0.6929 - acc: 0.5160 - val_loss: 0.6850 - val_acc: 0.5717
Epoch 2/100
100/100 [==============================] - 17s 170ms/step - loss: 0.6821 - acc: 0.5612 - val_loss: 0.6315 - val_acc: 0.5902
Epoch 3/100
100/100 [==============================] - 17s 165ms/step - loss: 0.6698 - acc: 0.5818 - val_loss: 0.6664 - val_acc: 0.6079
Epoch 4/100
100/100 [==============================] - 18s 175ms/step - loss: 0.6565 - acc: 0.5969 - val_loss: 0.7002 - val_acc: 0.6347
Epoch 5/100
100/100 [==============================] - 17s 167ms/step - loss: 0.6368 - acc: 0.6291 - val_loss: 0.5546 - val_acc: 0.6104
Epoch 6/100
100/100 [==============================] - 18s 181ms/step - loss: 0.6221 - acc: 0.6490 - val_loss: 0.5918 - val_acc: 0.6701
Epoch 7/100
100/100 [==============================] - 17s 166ms/step - loss: 0.6044 - acc: 0.6665 - val_loss: 0.5166 - val_acc: 0.6827
Epoch 8/100
100/100 [==============================] - 17s 170ms/step - loss: 0.5931 - acc: 0.6881 - val_loss: 0.5275 - val_acc: 0.6946
Epoch 9/100
100/100 [==============================] - 17s 171ms/step - loss: 0.5846 - acc: 0.6922 - val_loss: 0.4755 - val_acc: 0.6611
Epoch 10/100
100/100 [==============================] - 17s 174ms/step - loss: 0.5823 - acc: 0.6825 - val_loss: 0.4928 - val_acc: 0.7062
Epoch 11/100
100/100 [==============================] - 19s 189ms/step - loss: 0.5773 - acc: 0.6938 - val_loss: 0.4613 - val_acc: 0.7236
Epoch 12/100
100/100 [==============================] - 17s 171ms/step - loss: 0.5668 - acc: 0.7011 - val_loss: 0.5714 - val_acc: 0.7119
Epoch 13/100
100/100 [==============================] - 17s 170ms/step - loss: 0.5626 - acc: 0.7049 - val_loss: 0.6322 - val_acc: 0.7339
Epoch 14/100
100/100 [==============================] - 17s 168ms/step - loss: 0.5536 - acc: 0.7232 - val_loss: 0.5277 - val_acc: 0.7253
Epoch 15/100
100/100 [==============================] - 18s 176ms/step - loss: 0.5458 - acc: 0.7230 - val_loss: 0.4743 - val_acc: 0.6920
Epoch 16/100
100/100 [==============================] - 18s 177ms/step - loss: 0.5523 - acc: 0.7139 - val_loss: 0.4766 - val_acc: 0.7294
Epoch 17/100
100/100 [==============================] - 17s 169ms/step - loss: 0.5361 - acc: 0.7307 - val_loss: 0.4422 - val_acc: 0.7392
Epoch 18/100
100/100 [==============================] - 18s 183ms/step - loss: 0.5422 - acc: 0.7232 - val_loss: 0.5272 - val_acc: 0.7429
Epoch 19/100
100/100 [==============================] - 17s 167ms/step - loss: 0.5341 - acc: 0.7320 - val_loss: 0.4570 - val_acc: 0.7500
Epoch 20/100
100/100 [==============================] - 17s 170ms/step - loss: 0.5183 - acc: 0.7406 - val_loss: 0.5045 - val_acc: 0.7371
Epoch 21/100
100/100 [==============================] - 17s 166ms/step - loss: 0.5303 - acc: 0.7374 - val_loss: 0.6052 - val_acc: 0.7265
Epoch 22/100
100/100 [==============================] - 17s 174ms/step - loss: 0.5062 - acc: 0.7487 - val_loss: 0.5922 - val_acc: 0.7274
Epoch 23/100
100/100 [==============================] - 18s 182ms/step - loss: 0.5137 - acc: 0.7462 - val_loss: 0.4641 - val_acc: 0.7659
Epoch 24/100
100/100 [==============================] - 19s 185ms/step - loss: 0.5149 - acc: 0.7469 - val_loss: 0.3004 - val_acc: 0.7655
Epoch 25/100
100/100 [==============================] - 18s 184ms/step - loss: 0.5030 - acc: 0.7500 - val_loss: 0.4311 - val_acc: 0.7713
Epoch 26/100
100/100 [==============================] - 18s 182ms/step - loss: 0.5016 - acc: 0.7610 - val_loss: 0.5566 - val_acc: 0.7544
Epoch 27/100
100/100 [==============================] - 18s 182ms/step - loss: 0.5000 - acc: 0.7478 - val_loss: 0.7111 - val_acc: 0.7036
Epoch 28/100
100/100 [==============================] - 18s 175ms/step - loss: 0.4944 - acc: 0.7644 - val_loss: 0.3712 - val_acc: 0.7443
Epoch 29/100
100/100 [==============================] - 17s 168ms/step - loss: 0.5060 - acc: 0.7604 - val_loss: 0.5347 - val_acc: 0.7365
Epoch 30/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4963 - acc: 0.7614 - val_loss: 0.6272 - val_acc: 0.7500
Epoch 31/100
100/100 [==============================] - 17s 169ms/step - loss: 0.4890 - acc: 0.7613 - val_loss: 0.4844 - val_acc: 0.7655
Epoch 32/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4777 - acc: 0.7674 - val_loss: 0.5938 - val_acc: 0.7262
Epoch 33/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4810 - acc: 0.7683 - val_loss: 0.4125 - val_acc: 0.7640
Epoch 34/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4827 - acc: 0.7657 - val_loss: 0.3176 - val_acc: 0.7371
Epoch 35/100
100/100 [==============================] - 18s 176ms/step - loss: 0.4808 - acc: 0.7737 - val_loss: 0.4458 - val_acc: 0.7703
Epoch 36/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4739 - acc: 0.7770 - val_loss: 0.6801 - val_acc: 0.7693
Epoch 37/100
100/100 [==============================] - 16s 162ms/step - loss: 0.4687 - acc: 0.7740 - val_loss: 0.4553 - val_acc: 0.7500
Epoch 38/100
100/100 [==============================] - 17s 169ms/step - loss: 0.4764 - acc: 0.7688 - val_loss: 0.2923 - val_acc: 0.8015
Epoch 39/100
100/100 [==============================] - 17s 166ms/step - loss: 0.4574 - acc: 0.7841 - val_loss: 0.5701 - val_acc: 0.7887
Epoch 40/100
100/100 [==============================] - 18s 181ms/step - loss: 0.4547 - acc: 0.7872 - val_loss: 0.3487 - val_acc: 0.7887
Epoch 41/100
100/100 [==============================] - 17s 170ms/step - loss: 0.4524 - acc: 0.7842 - val_loss: 0.3621 - val_acc: 0.7448
Epoch 42/100
100/100 [==============================] - 17s 169ms/step - loss: 0.4494 - acc: 0.7817 - val_loss: 0.7426 - val_acc: 0.7951
Epoch 43/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4479 - acc: 0.7898 - val_loss: 0.4046 - val_acc: 0.7861
Epoch 44/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4454 - acc: 0.7907 - val_loss: 0.3987 - val_acc: 0.8033
Epoch 45/100
100/100 [==============================] - 18s 179ms/step - loss: 0.4439 - acc: 0.7924 - val_loss: 0.4113 - val_acc: 0.7945
Epoch 46/100
100/100 [==============================] - 16s 165ms/step - loss: 0.4365 - acc: 0.7973 - val_loss: 0.5503 - val_acc: 0.7868
Epoch 47/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4448 - acc: 0.7835 - val_loss: 0.3949 - val_acc: 0.7403
Epoch 48/100
100/100 [==============================] - 16s 163ms/step - loss: 0.4531 - acc: 0.7883 - val_loss: 0.4060 - val_acc: 0.7680
Epoch 49/100
100/100 [==============================] - 16s 163ms/step - loss: 0.4396 - acc: 0.7948 - val_loss: 0.5284 - val_acc: 0.7786
Epoch 50/100
100/100 [==============================] - 17s 171ms/step - loss: 0.4211 - acc: 0.8037 - val_loss: 0.5791 - val_acc: 0.7371
Epoch 51/100
100/100 [==============================] - 16s 162ms/step - loss: 0.4226 - acc: 0.8131 - val_loss: 0.5342 - val_acc: 0.7703
Epoch 52/100
100/100 [==============================] - 19s 189ms/step - loss: 0.4289 - acc: 0.7952 - val_loss: 0.3537 - val_acc: 0.7945
Epoch 53/100
100/100 [==============================] - 17s 172ms/step - loss: 0.4232 - acc: 0.8062 - val_loss: 0.2849 - val_acc: 0.7557
Epoch 54/100
100/100 [==============================] - 17s 171ms/step - loss: 0.4241 - acc: 0.7970 - val_loss: 0.5782 - val_acc: 0.8099
Epoch 55/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4165 - acc: 0.8059 - val_loss: 0.4404 - val_acc: 0.8052
Epoch 56/100
100/100 [==============================] - 17s 173ms/step - loss: 0.4268 - acc: 0.8068 - val_loss: 0.5490 - val_acc: 0.8073
Epoch 57/100
100/100 [==============================] - 17s 175ms/step - loss: 0.4130 - acc: 0.8046 - val_loss: 0.4626 - val_acc: 0.8022
Epoch 58/100
100/100 [==============================] - 17s 167ms/step - loss: 0.4253 - acc: 0.7981 - val_loss: 0.5076 - val_acc: 0.7824
Epoch 59/100
100/100 [==============================] - 17s 172ms/step - loss: 0.4237 - acc: 0.8005 - val_loss: 0.3535 - val_acc: 0.7945
Epoch 60/100
100/100 [==============================] - 17s 169ms/step - loss: 0.4021 - acc: 0.8109 - val_loss: 0.4156 - val_acc: 0.7697
Epoch 61/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4188 - acc: 0.8103 - val_loss: 0.3777 - val_acc: 0.7726
Epoch 62/100
100/100 [==============================] - 17s 169ms/step - loss: 0.4061 - acc: 0.8157 - val_loss: 0.5274 - val_acc: 0.8058
Epoch 63/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4003 - acc: 0.8125 - val_loss: 0.3102 - val_acc: 0.8235
Epoch 64/100
100/100 [==============================] - 16s 162ms/step - loss: 0.3960 - acc: 0.8185 - val_loss: 0.0757 - val_acc: 0.8189
Epoch 65/100
100/100 [==============================] - 17s 170ms/step - loss: 0.3921 - acc: 0.8232 - val_loss: 0.5657 - val_acc: 0.7849
Epoch 66/100
100/100 [==============================] - 17s 165ms/step - loss: 0.4045 - acc: 0.8150 - val_loss: 0.4963 - val_acc: 0.7674
Epoch 67/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3996 - acc: 0.8156 - val_loss: 0.5407 - val_acc: 0.8008
Epoch 68/100
100/100 [==============================] - 17s 165ms/step - loss: 0.3980 - acc: 0.8188 - val_loss: 0.2906 - val_acc: 0.8177
Epoch 69/100
100/100 [==============================] - 18s 179ms/step - loss: 0.3964 - acc: 0.8198 - val_loss: 0.3979 - val_acc: 0.8325
Epoch 70/100
100/100 [==============================] - 18s 176ms/step - loss: 0.3878 - acc: 0.8295 - val_loss: 0.4655 - val_acc: 0.8112
Epoch 71/100
100/100 [==============================] - 17s 168ms/step - loss: 0.4007 - acc: 0.8172 - val_loss: 0.4770 - val_acc: 0.7449
Epoch 72/100
100/100 [==============================] - 18s 175ms/step - loss: 0.3897 - acc: 0.8229 - val_loss: 0.2701 - val_acc: 0.7957
Epoch 73/100
100/100 [==============================] - 16s 165ms/step - loss: 0.3802 - acc: 0.8270 - val_loss: 0.5070 - val_acc: 0.7635
Epoch 74/100
100/100 [==============================] - 18s 182ms/step - loss: 0.3811 - acc: 0.8264 - val_loss: 0.6844 - val_acc: 0.7443
Epoch 75/100
100/100 [==============================] - 17s 170ms/step - loss: 0.3681 - acc: 0.8304 - val_loss: 0.2932 - val_acc: 0.8086
Epoch 76/100
100/100 [==============================] - 16s 165ms/step - loss: 0.3780 - acc: 0.8280 - val_loss: 0.5420 - val_acc: 0.8287
Epoch 77/100
100/100 [==============================] - 17s 173ms/step - loss: 0.3727 - acc: 0.8285 - val_loss: 0.2737 - val_acc: 0.8344
Epoch 78/100
100/100 [==============================] - 17s 172ms/step - loss: 0.3640 - acc: 0.8392 - val_loss: 0.5303 - val_acc: 0.8433
Epoch 79/100
100/100 [==============================] - 18s 176ms/step - loss: 0.3801 - acc: 0.8334 - val_loss: 0.2748 - val_acc: 0.8164
Epoch 80/100
100/100 [==============================] - 16s 165ms/step - loss: 0.3688 - acc: 0.8392 - val_loss: 0.1993 - val_acc: 0.8189
Epoch 81/100
100/100 [==============================] - 18s 185ms/step - loss: 0.3603 - acc: 0.8336 - val_loss: 0.3362 - val_acc: 0.8109
Epoch 82/100
100/100 [==============================] - 18s 175ms/step - loss: 0.3701 - acc: 0.8295 - val_loss: 0.6494 - val_acc: 0.8177
Epoch 83/100
100/100 [==============================] - 17s 166ms/step - loss: 0.3587 - acc: 0.8441 - val_loss: 0.3622 - val_acc: 0.8325
Epoch 84/100
100/100 [==============================] - 17s 173ms/step - loss: 0.3605 - acc: 0.8333 - val_loss: 0.4039 - val_acc: 0.8086
Epoch 85/100
100/100 [==============================] - 17s 168ms/step - loss: 0.3599 - acc: 0.8364 - val_loss: 0.2795 - val_acc: 0.8147
Epoch 86/100
100/100 [==============================] - 18s 180ms/step - loss: 0.3534 - acc: 0.8467 - val_loss: 0.4728 - val_acc: 0.7829
Epoch 87/100
100/100 [==============================] - 17s 168ms/step - loss: 0.3519 - acc: 0.8400 - val_loss: 0.5300 - val_acc: 0.8147
Epoch 88/100
100/100 [==============================] - 17s 170ms/step - loss: 0.3467 - acc: 0.8447 - val_loss: 0.4079 - val_acc: 0.8312
Epoch 89/100
100/100 [==============================] - 17s 173ms/step - loss: 0.3472 - acc: 0.8427 - val_loss: 0.2471 - val_acc: 0.8312
Epoch 90/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3540 - acc: 0.8438 - val_loss: 0.1968 - val_acc: 0.8401
Epoch 91/100
100/100 [==============================] - 17s 174ms/step - loss: 0.3328 - acc: 0.8508 - val_loss: 0.5539 - val_acc: 0.8357
Epoch 92/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3406 - acc: 0.8507 - val_loss: 0.4051 - val_acc: 0.8166
Epoch 93/100
100/100 [==============================] - 17s 169ms/step - loss: 0.3331 - acc: 0.8518 - val_loss: 0.5471 - val_acc: 0.8376
Epoch 94/100
100/100 [==============================] - 17s 171ms/step - loss: 0.3439 - acc: 0.8515 - val_loss: 0.3130 - val_acc: 0.8249
Epoch 95/100
100/100 [==============================] - 17s 170ms/step - loss: 0.3398 - acc: 0.8574 - val_loss: 0.4981 - val_acc: 0.8177
Epoch 96/100
100/100 [==============================] - 17s 169ms/step - loss: 0.3352 - acc: 0.8499 - val_loss: 0.1388 - val_acc: 0.7829
Epoch 97/100
100/100 [==============================] - 16s 164ms/step - loss: 0.3356 - acc: 0.8548 - val_loss: 0.4602 - val_acc: 0.8319
Epoch 98/100
100/100 [==============================] - 18s 181ms/step - loss: 0.3262 - acc: 0.8634 - val_loss: 0.3451 - val_acc: 0.8131
Epoch 99/100
100/100 [==============================] - 17s 170ms/step - loss: 0.3298 - acc: 0.8529 - val_loss: 0.2692 - val_acc: 0.8135
Epoch 100/100
100/100 [==============================] - 17s 172ms/step - loss: 0.3320 - acc: 0.8571 - val_loss: 0.6528 - val_acc: 0.7925
5.4절에서 이 모델을 사용하기 위해 모델을 저장합니다.
# 코드 5-15. 모델 저장하기
model.save('cats_and_dogs_small_2.h5')
결과 그래프를 다시 그려 보죠(그림 5-12와 5-13을 참고).
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
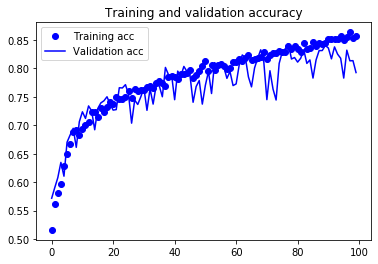
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
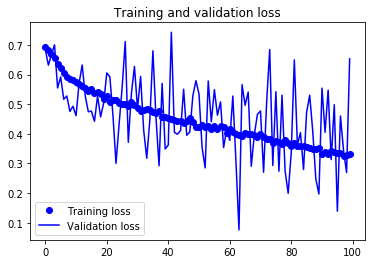
데이터 증식과 드롭아웃 덕택에 더이상 과대적합되지 않습니다. 훈련 곡선이 검증 곡선에 가깝게 따라가고 있습니다. 검증 데이터에서 82% 정확도를 달성하였습니다. 규제하지 않은 모델과 비교했을 때 15% 정도 향상되었습니다.
다른 규제 기법을 더 사용하고 네트워크의 파라미터를 튜닝하면(합성곱 층의 필터 수나 네트워크 층의 수 등) 86%나 87% 정도까지 더 높은 정확도를 얻을 수도 있습니다. 하지만 데이터가 적기 때문에 컨브넷을 처음부터 훈련해서 더 높은 정확도를 달성하기는 어렵습니다. 이런 상황에서 정확도를 높이기 위한 다음 단계는 사전 훈련된 모델을 사용하는 것입니다. 다음 두 절에서 이에 대해 집중적으로 살펴보겠습니다.
-
책의 깃허브에는 캐글에서 내려받은 train.zip 파일의 압축을 풀어 예제에 필요한 데이터를 ‘datasets/cats_and_dogs/train’ 폴더 아래에 넣어 놓았으므로 별도로 내려받을 필요가 없습니다. ↩
-
사실 캐글 사이트에는 별도의 테스트 데이터가 따로 있습니다. 이 테스트 데이터에는 타깃 레이블이 없고 참가자들은 테스트 데이터의 예측 레이블을 업로드하여 순위를 겨루게 됩니다. 이 책에서는 완전한 예제를 구성하기 위해 훈련 데이터로부터 훈련, 검증, 테스트 세트를 만듭니다. ↩
-
코드 5-7에 사용된
ImageDataGenerator클래스의flow_from_directory()메서드는 서브 디렉터리의 순서대로 레이블을 할당합니다. 여기에서는 ‘datasets/cats_and_dogs_small/train’ 디렉터리 아래 ‘cats’와 ‘dogs’가 순서대로 0, 1 레이블을 가집니다. 즉 ‘dogs’가 타깃 클래스가 되므로 최종 시그모이드의 출력은 강아지 이미지일 확률을 인코딩합니다.classes매개변수를 사용하면 디렉터리에 레이블이 할당되는 순서를 바꿀 수 있습니다.flow_from_directory(classes=['dogs', 'cats'])처럼 하면 ‘cats’가 타깃 클래스 1이 됩니다. ↩ -
keras.preprocessing아래의image,sequence,text모듈은Keras-Preprocessing패키지의 알리아스(alias)입니다. 이 패키지는 케라스와 함께 자동으로 설치됩니다. ↩ -
class_mode매개변수의 값은 다중 분류일 때는‘categorical’또는‘sparse’, 이진 분류일 때는‘binary’를 사용합니다.‘categorical’은 원-핫 인코딩된 2차원 배열을 반환하고‘sparse’는 정수 레이블을 담은 1차원 배열을 반환합니다.‘binary’는 0 또는 1로 채워진 1차원 배열을 반환합니다. 마지막으로 오토인코더처럼 입력을 타깃으로 하는 경우에는class_mode를‘input’이라고 지정합니다.class_mode의 기본값은‘categorical’입니다. ↩ -
파이썬의 제너레이터는 특수한 반복자이며
yield문을 사용하여 만든 경우를 제너레이터 함수, 소괄호와 리스트 내포 구문을 사용하는 경우를 제너레이터 표현식이라고 부릅니다. 파이썬의itertools아래에는 간단한 제너레이터를 대신할 수 있는 다양한 반복자가 준비되어 있습니다.count반복자를 사용하면 본문의generator()함수를count(1)로 간단하게 바꿀 수 있습니다. 리스트와 달리 반복자와 제너레이터는 전체 항목을 미리 만들지 않으므로 메모리 효율적입니다. 제너레이터에 관한 좀 더 자세한 설명은 저자의 블로그를 참고하세요(https://bit.ly/2KGrQxk). ↩ -
코드 5-7에서
validation_generator의 배치가 20개로 지정되었으므로 전체 검증 데이터(1,000개)를 사용하려면validation_steps를 50으로 설정합니다. ↩ -
회전 각도의 범위는
-rotation_range ~ +rotation_range가 됩니다. ↩ -
width_shift_range와height_shift_range가 1보다 큰 실수이거나 정수일 때는 픽셀 값으로 간주됩니다. 실수가 입력되면 이동 범위는(-width_shift_range, +width_shift_range)가 됩니다. 하나의 정수가 입력되면 이동 범위는(-width_shift_range, +width_shift_range)가 됩니다. 정수 리스트가 입력되면 하나를 랜덤하게 선택하고 다시 랜덤하게 음수 또는 양수로 바꾼 후 이동시킵니다. ↩ -
전단 변환은
rotation_range로 회전할 때 y축 방향으로 각도를 증가시켜 이미지를 변형시킵니다. ↩ -
실수가 입력되면
1-zoom_range ~ 1+zoom_range사이로 확대 또는 축소가 됩니다. [최소, 최대]처럼 확대 비율의 범위를 리스트로 전달할 수도 있습니다. ↩ -
예를 들어 도로 표지판 같은 경우 수평으로 뒤집힌 글씨를 학습시키는 것은 도움이 되지 않습니다. ↩
-
기본값인
‘nearest’는 인접한 픽셀을 사용하고‘constant’는cval매개변수의 값을 사용합니다. 그 외‘reflect’와‘wrap’이 있습니다. 전체 매개변수에 대한 설명은 케라스 문서를 참고하세요. ↩ -
파이썬에서 튜플이나 리스트 2개를 더하면 하나의 튜플로 연결됩니다.
flow()메서드는 배치 데이터를 기대하기 때문에 샘플 데이터에 배치 차원을 추가하여 4D 텐서로 만듭니다. ↩ -
이 장에서는 합성곱에서 추출한 특성 맵을 사용하여 클래스를 분류한다는 의미로 합성곱 층 위에 놓인 완전 연결 층들을 완전 연결 분류기(densely connected classifier)라고 부릅니다. ↩
-
테스트 세트도 증식되어서는 안 됩니다.
ImageDataGenerator에는 없지만 데이터 증식 방법 중 랜덤 크롭(crop)을 적용한다면 입력 데이터의 크기를 맞추기 위해 예외적으로 검증 세트와 테스트 세트도 크롭해야 합니다. 이때는 이미지의 가운데나 랜덤한 위치에서 한 번 크롭하여 검증 세트와 테스트 세트를 준비합니다. ↩
댓글남기기