5.3 사전 훈련된 컨브넷 사용하기
import keras
keras.__version__
Using TensorFlow backend.
'2.3.1'
작은 이미지 데이터셋에 딥러닝을 적용하는 일반적이고 매우 효과적인 방법은 사전 훈련된 네트워크를 사용하는 것입니다. 사전 훈련된 네트워크(pretrained network)는 일반적으로 대규모 이미지 분류 문제를 위해 대량의 데이터셋에서 미리 훈련되어 저장된 네트워크입니다. 원본 데이터셋이 충분히 크고 일반적이라면 사전 훈련된 네트워크에 의해 학습된 특성의 계층 구조는 실제 세상에 대한 일반적인 모델로 효율적인 역할을 할 수 있습니다. 새로운 문제가 원래 작업과 완전히 다른 클래스에 대한 것이더라도 이런 특성은 많은 컴퓨터 비전 문제에 유용합니다.
예를 들어 (대부분 동물이나 생활 용품으로 이루어진) ImageNet 데이터셋에 네트워크를 훈련합니다. 그다음 이 네트워크를 이미지에서 가구 아이템을 식별하는 것 같은 다른 용도로 사용할 수 있습니다. 학습된 특성을 다른 문제에 적용할 수 있는 이런 유연성은 이전의 많은 얕은 학습 방법과 비교했을 때 딥러닝의 핵심 장점입니다.
여기에서는 (1,400만 개의 레이블된 이미지와 1,000개의 클래스로 이루어진) ImageNet 데이터셋에서 훈련된 VGG16 구조를 사용하겠습니다. ImageNet 데이터셋은 다양한 종의 강아지와 고양이를 비롯하여 많은 동물들을 포함하고 있습니다. 그래서 강아지 vs. 고양이 분류 문제에 좋은 성능을 낼 것 같습니다. VGG16은 조금 오래되었고 최고 수준의 성능에는 못 미치며 최근의 다른 모델보다는 조금 무겁지만, 구조가 이전에 보았던 것과 비슷해서 새로운 개념을 도입하지 않고 이해하기 쉽습니다.
캐런 시몬연(Karen Simonyan)과 앤드류 지서먼(Andrew Zisserman)이 2014년에 개발한 VGG16 구조를 사용하겠습니다.1 아마 VGG가 처음 보는 모델 애칭일지 모르겠습니다. 이런 이름에는 VGG, ResNet, Inception, Inception-ResNet, Xception 등이 있습니다. 컴퓨터 비전을 위해 딥러닝을 계속 공부하다 보면 이런 이름을 자주 만나게 될 것입니다.
사전 훈련된 네트워크를 사용하는 두 가지 방법이 있습니다.
- 특성 추출(feature extraction)
- 미세 조정(fine tuning)
먼저 특성 추출부터 시작하죠.
5.3.1 특성 추출
특성 추출은 사전에 학습된 네트워크의 표현을 사용해 새로운 샘플에서 흥미로운 특성을 뽑아내는 것입니다. 이런 특성을 사용하여 새로운 분류기를 처음부터 훈련합니다.
앞서 보았듯이 컨브넷은 이미지 분류를 위해 두 부분으로 구성됩니다.
- 합성곱 기반층(convolutional base): 연속된 합성곱과 풀링 층
- 완전 연결 분류기
컨브넷의 경우 특성 추출은 사전에 훈련된 네트워크의 합성곱 기반층을 선택해 새로운 데이터를 통과시키고 그 출력으로 새로운 분류기를 훈련합니다.

그림 5-14. 같은 합성곱 기반 층을 유지하면서 분류기 바꾸기
완전 연결 분류기의 재사용은 일반적으로 권장하지 않습니다. 합성곱 층에 의해 학습된 표현이 더 일반적이어서 재사용 가능하기 때문입니다. 컨브넷의 특성 맵은 사진에 대한 일반적인 컨셉의 존재 여부를 기록한 맵이므로 주어진 컴퓨터 비전 문제에 상관없이 유용하게 사용할 수 있습니다. 하지만 분류기는 모델이 훈련된 클래스 집합에 특화되어 전체 사진에 어떤 클래스가 존재할 확률에 관한 정보만을 담고 있습니다. 더군다나 완전 연결 층에서 찾은 표현은 더 이상 입력 이미지에 있는 객체의 위치 정보를 가지고 있지 않습니다. 따라서 객체의 위치가 중요한 문제라면 완전 연결 층에서 만든 특성은 크게 쓸모가 없습니다.
특정 합성곱 층에서 추출한 표현의 일반성, 재사용성의 수준은 모델에 있는 층의 깊이에 달려 있습니다.
- 하위 층: 지역적이고 매우 일반적인 특성 맵 추출((에지, 색깔, 질감 등)
- 상위 층: 추상적인 개념 추출(‘강아지 눈’, ‘고양이 귀’ 등)
만약 새로운 데이터셋이 원본 모델이 훈련한 데이터셋과 많이 다르다면 전체 합성곱 기반층을 사용하는 것보다는 모델의 하위 층 몇 개만 특성 추출에 사용하는 것이 좋습니다.
ImageNet의 클래스 집합에는 여러 종류의 강아지와 고양이를 포함하고 있어 원본 모델의 완전 연결 층에 있는 정보를 재사용하는 것이 도움이 될 것 같습니다. 하지만 좀 더 일반적인 경우를 다루기 위해서 여기서는 완전 연결 층을 사용하지 않겠습니다.
ImageNet 데이터셋에 훈련된 VGG16 네트워크의 합성곱 기반층을 사용하여 강아지와 고양이 이미지에서 유용한 특성을 추출해 보겠습니다. 그런 다음 이 특성으로 강아지 vs. 고양이 분류기를 훈련합니다.
VGG16 모델은 케라스에 패키지로 포함되어 있습니다. keras.applications 모듈에서 import 할 수 있습니다.2 keras.applications 모듈에서 사용 가능한 이미지 분류 모델은 다음과 같습니다(모두 ImageNet 데이터셋에서 훈련되었습니다).
VGG16 모델을 만들어 보죠.
# 코드 5-16. VGG16 합성곱 기반 층 만들기
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
VGG16 함수에 세 개의 매개변수를 전달합니다.
weights는 모델을 초기화할 가중치 체크포인트(checkpoint)를 지정합니다.include_top은 네트워크의 최상위 완전 연결 분류기를 포함할지 안할지를 지정합니다. 기본값은 ImageNet의 1,000개의 클래스에 대응되는 완전 연결 분류기를 포함합니다. 별도의 (강아지와 고양이 2개의 클래스를 구분하는) 완전 연결 층을 추가하려고 하므로 이를 포함시키지 않습니다.input_shape은 네트워크에 주입할 이미지 텐서의 크기입니다. 이 매개변수는 선택사항입니다. 이 값을 지정하지 않으면 네트워크가 어떤 크기의 입력도 처리할 수 있습니다.8
다음은 VGG16 합성곱 기반층의 자세한 구조입니다. 이 구조는 앞에서 보았던 간단한 컨브넷과 비슷합니다.
conv_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
최종 특성 맵의 크기는 (4, 4, 512)입니다. 이 특성 위에 완전 연결 층을 놓을 것입니다.
이 지점에서 두 가지 방식이 가능합니다.
- 새로운 데이터셋에서 합성곱 기반층을 실행하고 출력을 넘파이 배열로 디스크에 저장합니다. 그다음 이 데이터를 이 책의 1부에서 보았던 것과 비슷한 독립된 완전 연결 분류기에 입력으로 사용합니다. 합성곱 연산은 전체 과정 중에서 가장 비싼 부분입니다. 이 방식은 모든 입력 이미지에 대해 합성곱 기반층을 한 번만 실행하면 되기 때문에 빠르고 비용이 적게 듭니다. 하지만 이런 이유 때문에 이 기법에는 데이터 증식을 사용할 수 없습니다.
- 준비한 모델(
conv_base) 위에Dense층을 쌓아 확장합니다. 그다음 입력 데이터에서 엔드-투-엔드로 전체 모델을 실행합니다. 모델에 노출된 모든 입력 이미지가 매번 합성곱 기반층을 통과하기 때문에 데이터 증식을 사용할 수 있습니다. 하지만 이런 이유로 이 방식은 첫 번째 방식보다 훨씬 비용이 많이 듭니다.
두 가지 방식을 모두 다루어 보겠습니다
데이터 증식을 사용하지 않는 빠른 특성 추출
먼저 앞서 소개한 ImageDataGenerator를 사용해 이미지와 레이블을 넘파이 배열로 추출하겠습니다. conv_base 모델의 predict 메서드를 호출하여 이 이미지에서 특성을 추출합니다.
# 코드 5-17. 사전 훈련된 합성곱 기반 층을 사용한 특성 추출하기
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = './datasets/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
# 제너레이터는 루프 안에서 무한하게 데이터를 만들어내므로 모든 이미지를 한 번씩 처리하고 나면 중지합니다
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
추출된 특성의 크기는 (samples, 4, 4, 512)입니다. 완전 연결 분류기에 주입하기 위해서 먼저 (samples, 8192) 크기로 펼칩니다.
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
그러고 나서 완전 연결 분류기를 정의하고(규제를 위해 드롭아웃을 사용합니다) 저장된 데이터와 레이블을 사용해 훈련합니다.
# 코드 5-18. 완전 연결 분류기를 정의하고 훈련하기
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))
Train on 2000 samples, validate on 1000 samples
Epoch 1/30
2000/2000 [==============================] - 1s 469us/step - loss: 0.6114 - acc: 0.6570 - val_loss: 0.4556 - val_acc: 0.8150
Epoch 2/30
2000/2000 [==============================] - 1s 411us/step - loss: 0.4349 - acc: 0.8130 - val_loss: 0.3680 - val_acc: 0.8550
Epoch 3/30
2000/2000 [==============================] - 1s 407us/step - loss: 0.3668 - acc: 0.8480 - val_loss: 0.3258 - val_acc: 0.8620
Epoch 4/30
2000/2000 [==============================] - 1s 412us/step - loss: 0.3117 - acc: 0.8755 - val_loss: 0.2999 - val_acc: 0.8790
Epoch 5/30
2000/2000 [==============================] - 1s 407us/step - loss: 0.2864 - acc: 0.8905 - val_loss: 0.2861 - val_acc: 0.8800
Epoch 6/30
2000/2000 [==============================] - 1s 407us/step - loss: 0.2675 - acc: 0.8935 - val_loss: 0.2735 - val_acc: 0.8860
Epoch 7/30
2000/2000 [==============================] - 1s 415us/step - loss: 0.2528 - acc: 0.8915 - val_loss: 0.2667 - val_acc: 0.8920
Epoch 8/30
2000/2000 [==============================] - 1s 416us/step - loss: 0.2323 - acc: 0.9095 - val_loss: 0.2695 - val_acc: 0.8860
Epoch 9/30
2000/2000 [==============================] - 1s 414us/step - loss: 0.2210 - acc: 0.9140 - val_loss: 0.2544 - val_acc: 0.9020
Epoch 10/30
2000/2000 [==============================] - 1s 411us/step - loss: 0.2049 - acc: 0.9265 - val_loss: 0.2516 - val_acc: 0.9000
Epoch 11/30
2000/2000 [==============================] - 1s 394us/step - loss: 0.1957 - acc: 0.9320 - val_loss: 0.2573 - val_acc: 0.8950
Epoch 12/30
2000/2000 [==============================] - 1s 411us/step - loss: 0.1876 - acc: 0.9325 - val_loss: 0.2482 - val_acc: 0.9000
Epoch 13/30
2000/2000 [==============================] - 1s 410us/step - loss: 0.1785 - acc: 0.9365 - val_loss: 0.2455 - val_acc: 0.9020
Epoch 14/30
2000/2000 [==============================] - 1s 409us/step - loss: 0.1690 - acc: 0.9380 - val_loss: 0.2489 - val_acc: 0.8990
Epoch 15/30
2000/2000 [==============================] - 1s 413us/step - loss: 0.1637 - acc: 0.9460 - val_loss: 0.2411 - val_acc: 0.9020
Epoch 16/30
2000/2000 [==============================] - 1s 411us/step - loss: 0.1599 - acc: 0.9450 - val_loss: 0.2388 - val_acc: 0.9030
Epoch 17/30
2000/2000 [==============================] - 1s 413us/step - loss: 0.1525 - acc: 0.9490 - val_loss: 0.2423 - val_acc: 0.9060
Epoch 18/30
2000/2000 [==============================] - 1s 410us/step - loss: 0.1506 - acc: 0.9430 - val_loss: 0.2400 - val_acc: 0.9060
Epoch 19/30
2000/2000 [==============================] - 1s 412us/step - loss: 0.1371 - acc: 0.9565 - val_loss: 0.2444 - val_acc: 0.9020
Epoch 20/30
2000/2000 [==============================] - 1s 412us/step - loss: 0.1309 - acc: 0.9580 - val_loss: 0.2376 - val_acc: 0.9050
Epoch 21/30
2000/2000 [==============================] - 1s 409us/step - loss: 0.1320 - acc: 0.9590 - val_loss: 0.2465 - val_acc: 0.9050
Epoch 22/30
2000/2000 [==============================] - 1s 402us/step - loss: 0.1234 - acc: 0.9585 - val_loss: 0.2387 - val_acc: 0.9050
Epoch 23/30
2000/2000 [==============================] - 1s 398us/step - loss: 0.1198 - acc: 0.9610 - val_loss: 0.2577 - val_acc: 0.8970
Epoch 24/30
2000/2000 [==============================] - 1s 405us/step - loss: 0.1180 - acc: 0.9615 - val_loss: 0.2421 - val_acc: 0.9050
Epoch 25/30
2000/2000 [==============================] - 1s 414us/step - loss: 0.1097 - acc: 0.9650 - val_loss: 0.2377 - val_acc: 0.9020
Epoch 26/30
2000/2000 [==============================] - 1s 416us/step - loss: 0.1073 - acc: 0.9680 - val_loss: 0.2409 - val_acc: 0.9030
Epoch 27/30
2000/2000 [==============================] - 1s 411us/step - loss: 0.0998 - acc: 0.9710 - val_loss: 0.2399 - val_acc: 0.9020
Epoch 28/30
2000/2000 [==============================] - 1s 405us/step - loss: 0.0946 - acc: 0.9690 - val_loss: 0.2478 - val_acc: 0.9020
Epoch 29/30
2000/2000 [==============================] - 1s 399us/step - loss: 0.0948 - acc: 0.9695 - val_loss: 0.2458 - val_acc: 0.9000
Epoch 30/30
2000/2000 [==============================] - 1s 415us/step - loss: 0.0890 - acc: 0.9755 - val_loss: 0.2563 - val_acc: 0.8990
2 개의 Dense 층만 처리하면 되기 때문에 훈련이 매우 빠릅니다. CPU를 사용하더라도 한 에포크에 걸리는 시간이 1초 미만입니다.
훈련 손실과 정확도 곡선을 살펴보죠(그림 5-15와 그림 5-16 참고).
# 코드 5-19 결과 그래프 그리기
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
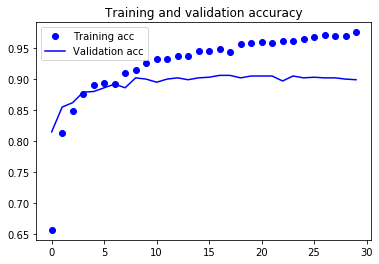
그림 5-15. 단순한 특성 추출 방식의 훈련 정확도와 검증 정확도
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
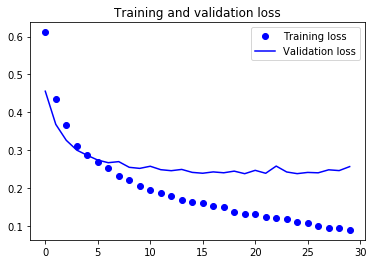
그림 5-16. 단순한 특성 추출 방식의 훈련 손실과 검증 손실
약 90%의 검증 정확도에 도달했습니다. 이전 절에서 처음부터 훈련시킨 작은 모델에서 얻은 것보다 훨씬 좋습니다. 하지만 이 그래프는 많은 비율로 드롭아웃을 사용했음에도 훈련을 시작하면서 거의 바로 과대적합되고 있다는 것을 보여 줍니다. 작은 이미지 데이터셋에서는 과대적합을 막기 위해 필수적인 데이터 증식을 사용하지 않았기 때문입니다.
데이터 증식을 사용한 특성 추출
이제 특성 추출을 위해 두 번째로 언급한 방법을 살펴보겠습니다. 이 방법은 훨씬 느리고 비용이 많이 들지만 훈련하는 동안 데이터 증식 기법을 사용할 수 있습니다. conv_base 모델을 확장하고 입력 데이터를 사용해 엔드-투-엔드로 실행합니다.
NOTE
이 기법은 연산 비용이 크기 때문에 GPU를 사용할 수 있을 때 시도해야 합니다. CPU에서는 적용하기 매우 힘듭니다. GPU를 사용할 수 없다면 첫 번째 방법을 사용하세요.
모델은 층과 동일하게 작동하므로 층을 추가하듯이 Sequential 모델에 (conv_base 같은) 다른 모델을 추가할 수 있습니다.9
# 코드 5-20. 합성곱 기반 층 위에 완전 연결 분류기 추가하기
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
이 모델의 구조는 다음과 같습니다:
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_3 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_4 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 16,812,353
Non-trainable params: 0
_________________________________________________________________
여기서 볼 수 있듯이 VGG16의 합성곱 기반 층은 14,714,688개의 매우 많은 파라미터를 가지고 있습니다. 합성곱 기반 층 위에 추가한 분류기는 200만 개의 파라미터를 가집니다.
모델을 컴파일하고 훈련하기 전에 합성곱 기반 층을 동결하는 것이 아주 중요합니다. 하나 이상의 층을 동결(freezing)한다는 것은 훈련하는 동안 가중치가 업데이트되지 않도록 막는다는 뜻입니다. 이렇게 하지 않으면 합성곱 기반 층에 의해 사전에 학습된 표현이 훈련하는 동안 수정될 것입니다. 맨 위의 Dense 층은 랜덤하게 초기화되었기 때문에 매우 큰 가중치 업데이트 값이 네트워크에 전파될 것입니다. 이는 사전에 학습된 표현을 크게 훼손하게 됩니다.
케라스에서는 trainable 속성을 False로 설정하여 네트워크를 동결할 수 있습니다.
print('conv_base를 동결하기 전 훈련되는 가중치의 수:',
len(model.trainable_weights))
conv_base를 동결하기 전 훈련되는 가중치의 수: 30
conv_base.trainable = False
print('conv_base를 동결한 후 훈련되는 가중치의 수:',
len(model.trainable_weights))
conv_base를 동결한 후 훈련되는 가중치의 수: 4
이렇게 설정하면 추가한 2개의 Dense 층의 가중치만 훈련될 것입니다. 층마다 2개씩(가중치 행렬과 편향 벡터10) 총 4개의 텐서가 훈련됩니다. 변경 사항을 적용하려면 먼저 모델을 컴파일해야 합니다. 컴파일 단계 후에 trainable 속성을 변경하면 반드시 모델을 다시 컴파일해야 합니다. 그렇지 않으면 변경 사항이 적용되지 않습니다.
이제 앞의 예제에서 사용했던 데이터 증식을 사용하여 모델 훈련을 시작할 수 있습니다.
# 코드 5-21. 동결된 합성곱 기반 층과 함께 모델을 엔드-투-엔드로 훈련하기
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지의 크기를 150 × 150로 변경합니다
target_size=(150, 150),
batch_size=20,
# binary_crossentropy 손실을 사용하므로 이진 레이블이 필요합니다
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Epoch 1/30
- 21s - loss: 0.5609 - acc: 0.7295 - val_loss: 0.3654 - val_acc: 0.8390
Epoch 2/30
- 21s - loss: 0.4148 - acc: 0.8285 - val_loss: 0.3762 - val_acc: 0.8820
Epoch 3/30
- 21s - loss: 0.3579 - acc: 0.8605 - val_loss: 0.4098 - val_acc: 0.8780
Epoch 4/30
- 21s - loss: 0.3215 - acc: 0.8635 - val_loss: 0.2473 - val_acc: 0.8960
Epoch 5/30
- 21s - loss: 0.3010 - acc: 0.8765 - val_loss: 0.2660 - val_acc: 0.8980
Epoch 6/30
- 21s - loss: 0.2927 - acc: 0.8855 - val_loss: 0.2320 - val_acc: 0.8980
Epoch 7/30
- 21s - loss: 0.2720 - acc: 0.8975 - val_loss: 0.1154 - val_acc: 0.8940
Epoch 8/30
- 21s - loss: 0.2548 - acc: 0.8950 - val_loss: 0.2207 - val_acc: 0.8920
Epoch 9/30
- 21s - loss: 0.2561 - acc: 0.8980 - val_loss: 0.2578 - val_acc: 0.9040
Epoch 10/30
- 21s - loss: 0.2483 - acc: 0.9040 - val_loss: 0.1934 - val_acc: 0.9030
Epoch 11/30
- 21s - loss: 0.2392 - acc: 0.9010 - val_loss: 0.2428 - val_acc: 0.9050
Epoch 12/30
- 21s - loss: 0.2377 - acc: 0.9030 - val_loss: 0.3463 - val_acc: 0.9020
Epoch 13/30
- 21s - loss: 0.2360 - acc: 0.9095 - val_loss: 0.4104 - val_acc: 0.9040
Epoch 14/30
- 21s - loss: 0.2329 - acc: 0.9050 - val_loss: 0.1884 - val_acc: 0.9040
Epoch 15/30
- 21s - loss: 0.2244 - acc: 0.9140 - val_loss: 0.1568 - val_acc: 0.8950
Epoch 16/30
- 21s - loss: 0.2211 - acc: 0.9115 - val_loss: 0.2995 - val_acc: 0.9050
Epoch 17/30
- 21s - loss: 0.2135 - acc: 0.9175 - val_loss: 0.0487 - val_acc: 0.9040
Epoch 18/30
- 21s - loss: 0.2168 - acc: 0.9170 - val_loss: 0.1768 - val_acc: 0.9060
Epoch 19/30
- 21s - loss: 0.2066 - acc: 0.9170 - val_loss: 0.2011 - val_acc: 0.9040
Epoch 20/30
- 21s - loss: 0.2102 - acc: 0.9190 - val_loss: 0.5184 - val_acc: 0.9050
Epoch 21/30
- 21s - loss: 0.2017 - acc: 0.9195 - val_loss: 0.1353 - val_acc: 0.9080
Epoch 22/30
- 21s - loss: 0.2077 - acc: 0.9115 - val_loss: 0.1621 - val_acc: 0.9070
Epoch 23/30
- 21s - loss: 0.2024 - acc: 0.9175 - val_loss: 0.2385 - val_acc: 0.9080
Epoch 24/30
- 21s - loss: 0.1909 - acc: 0.9265 - val_loss: 0.1933 - val_acc: 0.9030
Epoch 25/30
- 21s - loss: 0.1940 - acc: 0.9200 - val_loss: 0.1654 - val_acc: 0.9060
Epoch 26/30
- 21s - loss: 0.1825 - acc: 0.9305 - val_loss: 0.2976 - val_acc: 0.9030
Epoch 27/30
- 21s - loss: 0.1938 - acc: 0.9195 - val_loss: 0.2116 - val_acc: 0.9030
Epoch 28/30
- 21s - loss: 0.1941 - acc: 0.9225 - val_loss: 0.6071 - val_acc: 0.9040
Epoch 29/30
- 21s - loss: 0.1732 - acc: 0.9300 - val_loss: 0.4377 - val_acc: 0.9020
Epoch 30/30
- 21s - loss: 0.1845 - acc: 0.9310 - val_loss: 0.3385 - val_acc: 0.9010
model.save('cats_and_dogs_small_3.h5')
결과 그래프를 다시 그려 봅시다(그림 5-17과 그림 5-18 참고).
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
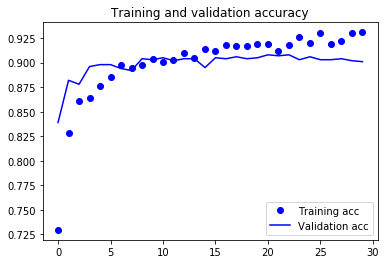
그림 5-17. 데이터 증식을 사용한 특성 추출 방식의 훈련 정확도와 검증 정확도
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
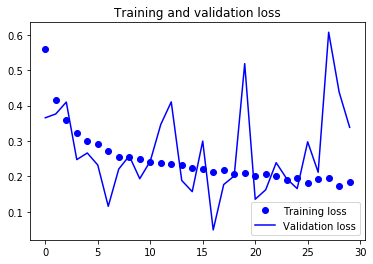
그림 5-18. 데이터 증식을 사용한 특성 추출 방식의 훈련 손실과 검증 손실
여기서 볼 수 있듯이 검증 정확도가 이전과 비슷하지만 처음부터 훈련시킨 소규모 컨브넷보다 과대적합이 줄었습니다.
5.3.2 미세 조정
모델을 재사용하는 데 널리 사용되는 또 하나의 기법은 특성 추출을 보완하는 미세 조정(fine-tuning)입니다(그림 5-19 참고). 미세 조정은 특성 추출에 사용했던 동결 모델의 상위 층 몇 개를 동결에서 해제하고 모델에 새로 추가한 층(여기서는 완전 연결 분류기)과 함께 훈련하는 것입니다. 주어진 문제에 조금 더 밀접하게 재사용 모델의 표현을 일부 조정하기 때문에 미세 조정이라고 부릅니다.

그림 5-19. VGG16 네트워크에서 마지막 합성곱 블록에 대한 미세 조정
앞서 랜덤하게 초기화된 상단 분류기를 훈련하기 위해 VGG16의 합성곱 기반층을 동결해야 한다고 말했습니다. 같은 이유로 맨 위에 있는 분류기가 훈련된 후에 합성곱 기반의 상위 층을 미세 조정할 수 있습니다. 분류기가 미리 훈련되지 않으면 훈련되는 동안 너무 큰 오차 신호가 네트워크에 전파됩니다. 이는 미세 조정될 층들이 사전에 학습한 표현들을 망가뜨리게 될 것입니다. 네트워크를 미세 조정하는 단계는 다음과 같습니다.
- 사전에 훈련된 기반 네트워크 위에 새로운 네트워크를 추가합니다.
- 기반 네트워크를 동결합니다.
- 새로 추가한 네트워크를 훈련합니다.
- 기반 네트워크에서 일부 층의 동결을 해제합니다.
- 동결을 해제한 층과 새로 추가한 층을 함께 훈련합니다.
처음 세 단계는 특성 추출을 할 때 이미 완료했습니다. 네 번째 단계를 진행해 보죠. conv_base의 동결을 해제하고 개별 층을 동결하겠습니다.
기억을 되살리기 위해 합성곱 기반층의 구조를 다시 확인해 보겠습니다.
conv_base.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
마지막 3 개의 합성곱 층을 미세 조정하겠습니다. 즉, block4_pool까지 모든 층은 동결되고 block5_conv1, block5_conv2, block5_conv3 층은 학습 대상이 됩니다.
왜 더 많은 층을 미세 조정하지 않을까요? 왜 전체 합성곱 기반층을 미세 조정하지 않을까요? 그렇게 할 수도 있지만 다음 사항을 고려해야 합니다.
- 합성곱 기반층에 있는 하위 층들은 좀 더 일반적이고 재사용 가능한 특성들을 인코딩합니다. 반면 상위 층은 좀 더 특화된 특성을 인코딩합니다. 새로운 문제에 재활용하도록 수정이 필요한 것은 구체적인 특성이므로 이들을 미세 조정하는 것이 유리합니다. 하위 층으로 갈수록 미세 조정에 대한 효과가 감소합니다.
- 훈련해야 할 파라미터가 많을수록 과대적합의 위험이 커집니다. 합성곱 기반층은 1천 5백만 개의 파라미터를 가지고 있습니다. 작은 데이터셋으로 전부 훈련하려고 하면 매우 위험합니다.
그러므로 이런 상황에서는 합성곱 기반층에서 최상위 2~3개의 층만 미세 조정하는 것이 좋습니다.
앞선 예제 코드에 이어서 미세 조정을 설정해보죠.
# 코드 5-22. 특정 층까지 모든 층 동결하기
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
이제 네트워크의 미세 조정을 시작하겠습니다. 학습률을 낮춘 RMSProp 옵티마이저를 사용합니다. 학습률을 낮추는 이유는 미세 조정하는 3개의 층에서 학습된 표현을 조금씩 수정하기 위해서입니다. 변경량이 너무 크면 학습된 표현에 나쁜 영향을 끼칠 수 있습니다.
미세 조정을 진행해 보죠.
# 코드 5-23. 모델 미세 조정하기
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/100
100/100 [==============================] - 25s 254ms/step - loss: 0.1960 - acc: 0.9205 - val_loss: 0.8679 - val_acc: 0.9160
Epoch 2/100
100/100 [==============================] - 25s 250ms/step - loss: 0.1655 - acc: 0.9340 - val_loss: 0.2790 - val_acc: 0.9190
Epoch 3/100
100/100 [==============================] - 25s 249ms/step - loss: 0.1273 - acc: 0.9515 - val_loss: 0.7621 - val_acc: 0.9130
Epoch 4/100
100/100 [==============================] - 25s 250ms/step - loss: 0.1227 - acc: 0.9540 - val_loss: 0.4474 - val_acc: 0.9220
Epoch 5/100
100/100 [==============================] - 25s 249ms/step - loss: 0.1116 - acc: 0.9580 - val_loss: 0.0262 - val_acc: 0.9260
Epoch 6/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0884 - acc: 0.9675 - val_loss: 0.4288 - val_acc: 0.9200
Epoch 7/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0804 - acc: 0.9720 - val_loss: 0.3037 - val_acc: 0.9270
Epoch 8/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0841 - acc: 0.9645 - val_loss: 0.3919 - val_acc: 0.9170
Epoch 9/100
100/100 [==============================] - 30s 304ms/step - loss: 0.0608 - acc: 0.9770 - val_loss: 0.0274 - val_acc: 0.9120
Epoch 10/100
100/100 [==============================] - 25s 252ms/step - loss: 0.0547 - acc: 0.9790 - val_loss: 0.0284 - val_acc: 0.9290
Epoch 11/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0526 - acc: 0.9795 - val_loss: 0.0596 - val_acc: 0.9250
Epoch 12/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0432 - acc: 0.9840 - val_loss: 0.3742 - val_acc: 0.9190
Epoch 13/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0379 - acc: 0.9860 - val_loss: 0.1190 - val_acc: 0.9230
Epoch 14/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0278 - acc: 0.9910 - val_loss: 0.3471 - val_acc: 0.9200
Epoch 15/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0387 - acc: 0.9850 - val_loss: 0.0092 - val_acc: 0.9190
Epoch 16/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0354 - acc: 0.9875 - val_loss: 0.0190 - val_acc: 0.9110
Epoch 17/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0316 - acc: 0.9910 - val_loss: 0.1035 - val_acc: 0.9300
Epoch 18/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0229 - acc: 0.9940 - val_loss: 0.1033 - val_acc: 0.9170
Epoch 19/100
100/100 [==============================] - 25s 252ms/step - loss: 0.0194 - acc: 0.9940 - val_loss: 0.0842 - val_acc: 0.9300
Epoch 20/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0248 - acc: 0.9930 - val_loss: 0.0891 - val_acc: 0.9320
Epoch 21/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0244 - acc: 0.9935 - val_loss: 0.7053 - val_acc: 0.9300
Epoch 22/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0219 - acc: 0.9945 - val_loss: 0.1857 - val_acc: 0.9260
Epoch 23/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0229 - acc: 0.9915 - val_loss: 0.2292 - val_acc: 0.9290
Epoch 24/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0119 - acc: 0.9965 - val_loss: 0.1663 - val_acc: 0.9230
Epoch 25/100
100/100 [==============================] - 25s 252ms/step - loss: 0.0177 - acc: 0.9935 - val_loss: 0.2815 - val_acc: 0.9170
Epoch 26/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0166 - acc: 0.9960 - val_loss: 0.2325 - val_acc: 0.9210
Epoch 27/100
100/100 [==============================] - 25s 255ms/step - loss: 0.0134 - acc: 0.9950 - val_loss: 0.3211 - val_acc: 0.9320
Epoch 28/100
100/100 [==============================] - 26s 256ms/step - loss: 0.0201 - acc: 0.9930 - val_loss: 0.0152 - val_acc: 0.9360
Epoch 29/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0135 - acc: 0.9965 - val_loss: 1.5522e-04 - val_acc: 0.9350
Epoch 30/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0067 - acc: 0.9990 - val_loss: 0.0110 - val_acc: 0.9360
Epoch 31/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0105 - acc: 0.9975 - val_loss: 0.0930 - val_acc: 0.9290
Epoch 32/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0085 - acc: 0.9980 - val_loss: 0.3534 - val_acc: 0.9320
Epoch 33/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0079 - acc: 0.9980 - val_loss: 0.0012 - val_acc: 0.9300
Epoch 34/100
100/100 [==============================] - 25s 251ms/step - loss: 0.0109 - acc: 0.9965 - val_loss: 0.0716 - val_acc: 0.9230
Epoch 35/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0076 - acc: 0.9980 - val_loss: 0.3224 - val_acc: 0.9130
Epoch 36/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0104 - acc: 0.9980 - val_loss: 0.0012 - val_acc: 0.9330
Epoch 37/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0100 - acc: 0.9965 - val_loss: 0.5410 - val_acc: 0.9250
Epoch 38/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0053 - acc: 0.9990 - val_loss: 0.1100 - val_acc: 0.9150
Epoch 39/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0059 - acc: 0.9985 - val_loss: 0.0018 - val_acc: 0.9120
Epoch 40/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0063 - acc: 0.9985 - val_loss: 0.0023 - val_acc: 0.9240
Epoch 41/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0059 - acc: 0.9970 - val_loss: 0.1572 - val_acc: 0.9260
Epoch 42/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0051 - acc: 0.9980 - val_loss: 1.6257 - val_acc: 0.9300
Epoch 43/100
100/100 [==============================] - 25s 247ms/step - loss: 0.0059 - acc: 0.9975 - val_loss: 0.5513 - val_acc: 0.9250
Epoch 44/100
100/100 [==============================] - 25s 247ms/step - loss: 0.0090 - acc: 0.9955 - val_loss: 0.7300 - val_acc: 0.9270
Epoch 45/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0064 - acc: 0.9985 - val_loss: 0.3463 - val_acc: 0.9330
Epoch 46/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0055 - acc: 0.9980 - val_loss: 0.0022 - val_acc: 0.9280
Epoch 47/100
100/100 [==============================] - 25s 252ms/step - loss: 0.0031 - acc: 0.9985 - val_loss: 0.3990 - val_acc: 0.9330
Epoch 48/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0093 - acc: 0.9980 - val_loss: 0.0063 - val_acc: 0.9270
Epoch 49/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0057 - acc: 0.9980 - val_loss: 0.1155 - val_acc: 0.9310
Epoch 50/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0096 - acc: 0.9955 - val_loss: 0.5194 - val_acc: 0.9120
Epoch 51/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0044 - acc: 0.9985 - val_loss: 0.3469 - val_acc: 0.9350
Epoch 52/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0042 - acc: 0.9985 - val_loss: 0.1355 - val_acc: 0.9300
Epoch 53/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0042 - acc: 0.9980 - val_loss: 0.6642 - val_acc: 0.9350
Epoch 54/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0062 - acc: 0.9975 - val_loss: 0.4946 - val_acc: 0.9270
Epoch 55/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0037 - acc: 0.9990 - val_loss: 0.0793 - val_acc: 0.9340
Epoch 56/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0033 - acc: 0.9985 - val_loss: 0.2958 - val_acc: 0.9280
Epoch 57/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0125 - acc: 0.9965 - val_loss: 9.2789e-05 - val_acc: 0.9310
Epoch 58/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0028 - acc: 0.9995 - val_loss: 0.9494 - val_acc: 0.9330
Epoch 59/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0016 - acc: 1.0000 - val_loss: 0.0315 - val_acc: 0.9210
Epoch 60/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0103 - acc: 0.9975 - val_loss: 0.1671 - val_acc: 0.9200
Epoch 61/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0033 - acc: 0.9995 - val_loss: 0.4171 - val_acc: 0.9280
Epoch 62/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0025 - acc: 0.9995 - val_loss: 0.0532 - val_acc: 0.9340
Epoch 63/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0044 - acc: 0.9990 - val_loss: 1.0046 - val_acc: 0.9310
Epoch 64/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0063 - acc: 0.9990 - val_loss: 0.3756 - val_acc: 0.9180
Epoch 65/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0032 - acc: 0.9985 - val_loss: 0.0271 - val_acc: 0.9290
Epoch 66/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0038 - acc: 0.9990 - val_loss: 0.0519 - val_acc: 0.9350
Epoch 67/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0030 - acc: 0.9985 - val_loss: 0.0012 - val_acc: 0.9320
Epoch 68/100
100/100 [==============================] - 25s 253ms/step - loss: 0.0010 - acc: 1.0000 - val_loss: 0.5425 - val_acc: 0.9310
Epoch 69/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0023 - acc: 0.9990 - val_loss: 1.0680 - val_acc: 0.9270
Epoch 70/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0012 - acc: 0.9995 - val_loss: 4.5500e-05 - val_acc: 0.9360
Epoch 71/100
100/100 [==============================] - 25s 251ms/step - loss: 0.0046 - acc: 0.9990 - val_loss: 0.0630 - val_acc: 0.9300
Epoch 72/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0031 - acc: 0.9985 - val_loss: 0.5814 - val_acc: 0.9270
Epoch 73/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0021 - acc: 0.9990 - val_loss: 0.3313 - val_acc: 0.9360
Epoch 74/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0021 - acc: 0.9990 - val_loss: 0.9863 - val_acc: 0.9100
Epoch 75/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0020 - acc: 0.9995 - val_loss: 8.5925e-04 - val_acc: 0.9300
Epoch 76/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0016 - acc: 0.9995 - val_loss: 9.6693e-04 - val_acc: 0.9350
Epoch 77/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0018 - acc: 0.9995 - val_loss: 0.0311 - val_acc: 0.9350
Epoch 78/100
100/100 [==============================] - 25s 255ms/step - loss: 0.0023 - acc: 0.9990 - val_loss: 0.8617 - val_acc: 0.9280
Epoch 79/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0022 - acc: 0.9995 - val_loss: 0.9652 - val_acc: 0.9390
Epoch 80/100
100/100 [==============================] - 25s 251ms/step - loss: 0.0010 - acc: 1.0000 - val_loss: 6.6422e-04 - val_acc: 0.9340
Epoch 81/100
100/100 [==============================] - 25s 247ms/step - loss: 0.0031 - acc: 0.9995 - val_loss: 0.1927 - val_acc: 0.9370
Epoch 82/100
100/100 [==============================] - 25s 247ms/step - loss: 0.0069 - acc: 0.9985 - val_loss: 1.8762 - val_acc: 0.9350
Epoch 83/100
100/100 [==============================] - 25s 248ms/step - loss: 7.2210e-04 - acc: 1.0000 - val_loss: 0.3538 - val_acc: 0.9380
Epoch 84/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0024 - acc: 0.9990 - val_loss: 1.4869e-05 - val_acc: 0.9360
Epoch 85/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0042 - acc: 0.9985 - val_loss: 0.2500 - val_acc: 0.9310
Epoch 86/100
100/100 [==============================] - 25s 251ms/step - loss: 0.0010 - acc: 1.0000 - val_loss: 0.0698 - val_acc: 0.9330
Epoch 87/100
100/100 [==============================] - 25s 250ms/step - loss: 0.0025 - acc: 0.9990 - val_loss: 0.0117 - val_acc: 0.9390
Epoch 88/100
100/100 [==============================] - 25s 254ms/step - loss: 0.0014 - acc: 0.9995 - val_loss: 0.0092 - val_acc: 0.9410
Epoch 89/100
100/100 [==============================] - 25s 252ms/step - loss: 7.0488e-04 - acc: 1.0000 - val_loss: 0.1588 - val_acc: 0.9300
Epoch 90/100
100/100 [==============================] - 25s 251ms/step - loss: 0.0048 - acc: 0.9990 - val_loss: 0.0236 - val_acc: 0.9430
Epoch 91/100
100/100 [==============================] - 25s 247ms/step - loss: 0.0022 - acc: 0.9990 - val_loss: 0.7801 - val_acc: 0.9360
Epoch 92/100
100/100 [==============================] - 25s 249ms/step - loss: 5.9879e-04 - acc: 1.0000 - val_loss: 3.3976e-05 - val_acc: 0.9350
Epoch 93/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0025 - acc: 0.9985 - val_loss: 0.1140 - val_acc: 0.9330
Epoch 94/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0041 - acc: 0.9985 - val_loss: 1.4073 - val_acc: 0.9360
Epoch 95/100
100/100 [==============================] - 25s 250ms/step - loss: 8.4742e-04 - acc: 1.0000 - val_loss: 0.2822 - val_acc: 0.9390
Epoch 96/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0045 - acc: 0.9990 - val_loss: 0.1103 - val_acc: 0.9320
Epoch 97/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0068 - acc: 0.9980 - val_loss: 0.7420 - val_acc: 0.9300
Epoch 98/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0019 - acc: 0.9995 - val_loss: 0.5260 - val_acc: 0.9370
Epoch 99/100
100/100 [==============================] - 25s 249ms/step - loss: 0.0063 - acc: 0.9985 - val_loss: 1.7355e-04 - val_acc: 0.9330
Epoch 100/100
100/100 [==============================] - 25s 248ms/step - loss: 0.0023 - acc: 0.9990 - val_loss: 0.5399 - val_acc: 0.9380
model.save('cats_and_dogs_small_4.h5')
이전과 동일한 코드로 결과 그래프를 그려 보겠습니다(그림 5-20과 그림 5-21 참고).
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
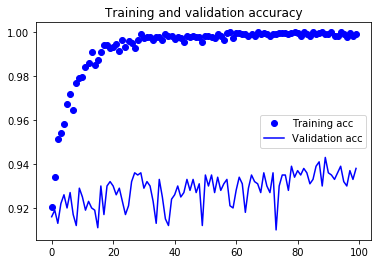
그림 5-20. 미세 조정을 사용한 훈련 정확도와 검증 정확도
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
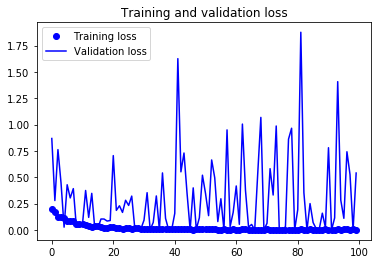
그림 5-21. 미세 조정을 사용한 훈련 손실과 검증 손실
그래프가 불규칙하게 보입니다. 그래프를 보기 쉽게 하기 위해 지수 이동 평균(exponential moving averages)으로 정확도와 손실 값을 부드럽게 표현할 수 있습니다.
다음은 지수 이동 평균을 구하기 위한 간단한 함수입니다(그림 5-22와 그림 5-23 참고).
# 코드 5-24. 부드러운 그래프 그리기
def smooth_curve(points, factor=0.8):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
plt.plot(epochs,
smooth_curve(acc), 'bo', label='Smoothed training acc')
plt.plot(epochs,
smooth_curve(val_acc), 'b', label='Smoothed validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
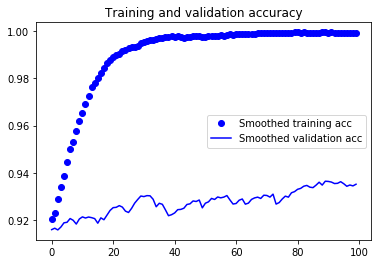
그림 5-22. 미세 조정을 사용한 훈련 정확도와 검증 정확도의 부드러운 곡선
plt.figure()
plt.plot(epochs,
smooth_curve(loss), 'bo', label='Smoothed training loss')
plt.plot(epochs,
smooth_curve(val_loss), 'b', label='Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
<matplotlib.legend.Legend at 0x28a44841cc8>
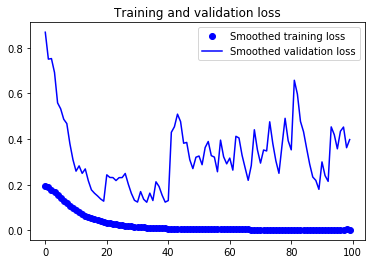
검증 정확도 곡선이 훨씬 깨끗하게 보입니다. 정확도가 확실히 1% 이상 향상되었습니다.
손실 곡선은 실제 어떤 향상을 얻지 못했습니다(사실 악화되었습니다). 손실히 감소되지 않았는데 어떻게 정확도가 안정되거나 향상될 수 있을까요? 답은 간단합니다. 그래프는 개별적인 손실 값의 평균을 그린 것입니다. 하지만 정확도에 영향을 미치는 것은 손실 값의 분포이지 평균이 아닙니다. 정확도는 모델이 예측한 클래스 확률이 어떤 임계값을 넘었는지에 대한 결과이기 때문입니다. 모델이 더 향상더라도 평균 손실에 반영되지 않을 수 있습니다.11
이제 마지막으로 테스트 데이터에서 이 모델을 평가하겠습니다.
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
Found 1000 images belonging to 2 classes.
test acc: 0.9340000152587891
92%의 테스트 정확도를 얻을 것입니다. 이 데이터셋을 사용한 원래 캐글 경연 대회에서 꽤 높은 순위입니다. 하지만 최신 딥러닝 기법으로 훈련 데이터의 일부분(약 10%)만을 사용해서 이런 결과를 달성했습니다. 20,000개의 샘플에서 훈련하는 것과 2,000개의 샘플에서 훈련하는 것 사이에는 아주 큰 차이점이 있습니다!
5.3.3 정리
다음은 앞의 두 절에 있는 예제로부터 배운 것들입니다.
- 컨브넷은 컴퓨터 비전 작업에 가장 뛰어난 머신 러닝 모델입니다. 아주 작은 데이터셋에서도 처음부터 훈련해서 괜찮은 성능을 낼 수 있습니다.
- 작은 데이터셋에서는 과대적합이 큰 문제입니다. 데이터 증식은 이미지 데이터를 다룰 때 과대적합을 막을 수 있는 강력한 방법입니다.
- 특성 추출 방식으로 새로운 데이터셋에 기존의 컨브넷을 쉽게 재사용할 수 있습니다. 작은 이미지 데이터셋으로 작업할 때 효과적인 기법입니다.
- 특성 추출을 보완하기 위해 미세 조정을 사용할 수 있습니다. 미세 조정은 기존 모델에서 사전에 학습한 표현의 일부를 새로운 문제에 적응시킵니다. 이 기법은 조금 더 성능을 끌어올립니다.
지금까지 이미지 분류 문제에서 특히 작은 데이터셋을 다루기 위한 좋은 도구들을 배웠습니다.
-
Karen Simonyan and Andrew Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” arXiv (2014), https://arxiv.org/abs/1409.1556. ↩
-
keras.applications 아래의 모듈들은 Keras-Applications 패키지의 알리아스입니다. 이 패키지는 Keras와 함께 자동으로 설치됩니다. 본문에 나열된 것 이외에도 다음 모델들이 포함되어 있습니다.
- InceptionResNetV2(Christian Szegedy, et al. “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning,” arXiv (2016), https://arxiv.org/abs/1602.07261).
- MobileNetV2(Mark Sandler, et al. “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” arXiv (2018), https://arxiv.org/abs/1801.04381).
- DenseNet(Gao Huang, et al. “Densely Connected Convolutional Networks,” arXiv (2016), https://arxiv.org/abs/1608.06993).
- NASNet(Barret Zoph, et al. “Learning Transferable Architectures for Scalable Image Recognition,” arXiv (2017), https://arxiv.org/abs/1707.07012).
-
François Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” arXiv (2016), https://arxiv.org/abs/1610.02357. ↩
-
Christian Szegedy, et al. “Rethinking the Inception Architecture for Computer Vision,” arXiv (2015), https://arxiv.org/abs/1512.00567. ↩
-
Kaiming He, et al. “Deep Residual Learning for Image Recognition,” arXiv (2015), https://arxiv.org/abs/1512.03385. ↩
-
VGG19는 합성곱 층 16개, 완전 연결 층 3개로 이루어져 있습니다. VGG16은 합성곱 층 13개, 완전 연결 층이 3개입니다. ↩
-
Andrew G. Howard, et al. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” arXiv (2017), https://arxiv.org/abs/1704.04861. ↩
-
include_top이 기본값 True이면 합성곱 층 위에 완전 연결 층이 추가되기 때문에input_shape이 원본 모델과 동일한(224, 224, 3)이 되어야 합니다. ↩ -
케라스에서 신경망을 위한 가장 상위 클래스인
Layer클래스를 상속하여keras.layers아래의 층들이 구현됩니다. 또Layer클래스를 상속한Network클래스가 비순환 유향 그래프를 구현하고Network클래스를 상속한Model클래스는 신경망의 훈련 과정을 구현합니다. 따라서Model클래스를 상속한Sequential클래스는 층은 물론 다른 모델도 추가할 수 있습니다. ↩ -
예를 들어
block1_conv1층의 경우 윈도우 크기가 3×3, 입력 채널의 깊이가 3, 필터의 개수가 64개이므로 가중치 행렬의 크기는(3, 3, 3, 64)가 됩니다. 편향은 필터마다 하나씩 필요하므로(64,)의 크기를 가집니다. 모델의trainable_weights속성을 출력하면 전체 가중치 크기를 확인할 수 있습니다. ↩ -
4.5.5절에서 설명했듯이 정확도를 직접 최적화할 수 없고 크로스엔트로피 같은 대리 손실 함수(surrogate loss function)를 사용하기 때문에 이런 현상이 발생할 수 있습니다. ↩
댓글남기기