5.4 컨브넷의 학습 시각화하기
import keras
keras.__version__
Using TensorFlow backend.
'2.3.1'
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
딥러닝 모델을 ‘블랙 박스(black box)’ 같다라고 자주 이야기 하는데 사람이 이해하기 쉬운 형태로 나타내기 어렵기 때문입니다. 하지만 컨브넷은 시각적인 개념을 학습한 것이기 때문에 시각화하기 아주 좋습니다. 2013년부터 이런 표현들을 시각화하고 해석하는 다양한 기법들이 개발되었는데 여기선 가장 사용이 편하고 유용한 세 가지 기법을 다뤄봅니다.
- 컨브넷 중간층의 출력(중간층에 있는 활성화)을 시각화하기: 연속된 컨브넷 층이 입력을 어떻게 변형시키는지, 개별적인 컨브넷 필터가 갖는 의미가 무엇인지 이해하는데 도움이 됩니다.
- 컨브넷 필터를 시각화하기: 컨브넷의 필터가 찾으려는 시각적인 패턴과 개념이 무엇인지 상세하게 이해하는 데 도움이 됩니다.
- 클래스 활성화에 대한 히트맵(heatmap)1을 이미지에 시각화하기: 어느 부분이 클래스 활성화에 얼만큼 기여했는지 이해하고 이미지에서 객체 위치를 추정(localization)하는데 도움이 됩니다.
첫 번째 중간 층의 활성화 시각화하기 기법에는 5.2절에 있는 강아지 vs. 고양이 분류 문제에서 처음부터 훈련시킨 작은 컨브넷을, 다른 두 가지 기법에는 5.3절에 소개된 VGG16 모델을 사용하겠습니다.
5.4.1 중간 층의 활성화 시각화하기
중간 층의 활성화 시각화는 어떤 입력이 주어졌을 때 네트워크에 있는 여러 합성곱과 풀링 층이 출력하는 특성 맵을 그리는 것입니다(층의 출력이 활성화 함수의 출력이라서 종종 활성화(activation)라고 부릅니다). 이 방법은 네트워크에의해 학습된 필터들이 어떻게 입력을 분해하는지 보여줍니다.
넓이, 높이, 깊이(채널)의 세 개 차원에 대해 특성 맵을 시각화하는 것이 좋습니다. 또한, 각 채널은 비교적 독립적인 특성을 인코딩하므로 특성 맵의 각 채널 내용을 독립적인 2D 이미지로 그리는 것이 괜찮은 방법입니다.
5.2절에서 저장했던 모델을 로드하여 시작해 보죠.
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
model.summary() # 기억을 되살리기 위해서 모델 구조를 출력합니다
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 6272) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 6272) 0
_________________________________________________________________
dense_3 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_4 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
그다음 네트워크를 훈련할 때 사용했던 이미지에 포함되지 않은 고양이 사진 하나를 입력 이미지로 선택합니다.
# 코드 5-25. 개별 이미지 전처리하기
img_path = './datasets/cats_and_dogs_small/test/cats/cat.1700.jpg'
# 이미지를 4D 텐서로 변경합니다
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
# 배치 차원을 추가
# img_tensor = img_tensor.reshape((1,) + img_tensor.shape)
img_tensor = np.expand_dims(img_tensor, axis=0)
# 모델이 훈련될 때 입력에 적용한 전처리 방식을 동일하게 사용합니다
img_tensor /= 255.
# 이미지 텐서의 크기는 (1, 150, 150, 3)입니다
print(img_tensor.shape)
(1, 150, 150, 3)
사진을 출력해 보겠습니다.
# 코드 5-26. 테스트 사진 출력하기
import matplotlib.pyplot as plt
plt.imshow(img_tensor[0])
plt.show()

확인하고 싶은 특성 맵을 추출하기 위해 이미지 배치를 입력으로 받아 모든 합성곱과 풀링 층의 활성화를 출력하는 다중 출력 모델을 만들 것입니다. 이를 위해 케라스의 Model 클래스를 사용하겠습니다.
일반적으로 모델은 몇 개의 입력과 출력이라도 가질 수 있습니다. 지금까지 본 모델은 정확히 하나의 입력과 하나의 출력만을 가졌습니다. 핑합니다. Model 클래스를 사용하면 여러 개의 출력을 가진 모델을 만들 수
있습니다. 더 자세한 내용은 7.1을 참고하세요.
# 코드 5-27. 입력 텐서와 출력 텐서의 리스트로 모델 객체 만들기
from keras import models
# 상위 8개 층의 출력을 추출합니다:
layer_outputs = [layer.output for layer in model.layers[:8]]
# 입력에 대해 8개 층의 출력을 반환하는 모델을 만듭니다:
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
입력 이미지가 주입될 때 이 모델은 원본 모델의 활성화 값을 반환합니다. 이 모델이 이 모델이 이 책에서는 처음 나오는 다중 출력 모델입니다. 일반적으로 모델은 몇 개의 입력과 출력이라도 가질 수 있습니다. 습니다. 일반적으로 모델은 몇 개의 입력과 출력이라도 가질 수 있습니
# 코드 5-28. 예측 모드로 모델 실행하기
# 층의 활성화마다 하나씩 8개의 넘파이 배열로 이루어진 리스트를 반환합니다:
activations = activation_model.predict(img_tensor)
예를 들어 다음이 고양이 이미지에 대한 첫 번째 합성곱 층의 활성화 값입니다.
first_layer_activation = activations[0]
print(first_layer_activation.shape)
(1, 148, 148, 32)
32개의 채널을 가진 148×148 크기의 특성 맵입니다. 원본 모델의 첫 번째 층 활성화 중에서 20번째 채널을 그려 보겠습니다.
# 코드 5-29. 20번째 채널 시각화하기
plt.matshow(first_layer_activation[0, :, :, 19], cmap='viridis')
plt.show()

그림 5-25. 고양이 테스트 사진에서 첫 번째 층의 활성화 중 20번째 채널
이 채널은 대각선 에지를 감지하도록 인코딩된 것 같습니다.
6번째 채널을 그려 보죠(그림 5-26 참고). 합성곱 층이 학습한 필터는 고정적이지 않아 책과 다를 수 있습니다.
# 코드 5-30. 16번째 채널 시각화하기
plt.matshow(first_layer_activation[0, :, :, 5], cmap='viridis')
plt.show()

그림 5-26. 고양이 테스트 사진에서 첫 번째 층의 활성화 중 16번째 채널
이 채널은 ‘밝은 녹색 점’을 감지하는 것 같아 고양이 눈을 인코딩하기 좋습니다.
이제 네트워크의 모든 활성화를 시각화해 보겠습니다(그림 5-27 참고). 8개의 활성화 맵에서 추출한 모든 채널을 그리기 위해 하나의 큰 이미지 텐서에 추출한 결과를 나란히 쌓겠습니다.
# 코드 5-31. 중간층의 모든 활성화에 있는 채널 시각화하기
# 층의 이름을 그래프 제목으로 사용합니다
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16
# 특성 맵을 그립니다
for layer_name, layer_activation in zip(layer_names, activations):
# 특성 맵에 있는 특성의 수
n_features = layer_activation.shape[-1]
# 특성 맵의 크기는 (1, size, size, n_features)입니다
size = layer_activation.shape[1]
# 활성화 채널을 위한 그리드 크기를 구합니다
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size))
# 각 활성화를 하나의 큰 그리드에 채웁니다
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,
:, :,
col * images_per_row + row]
# 그래프로 나타내기 좋게 특성을 처리합니다
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col * size : (col + 1) * size,
row * size : (row + 1) * size] = channel_image
# 그리드를 출력합니다
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
plt.show()



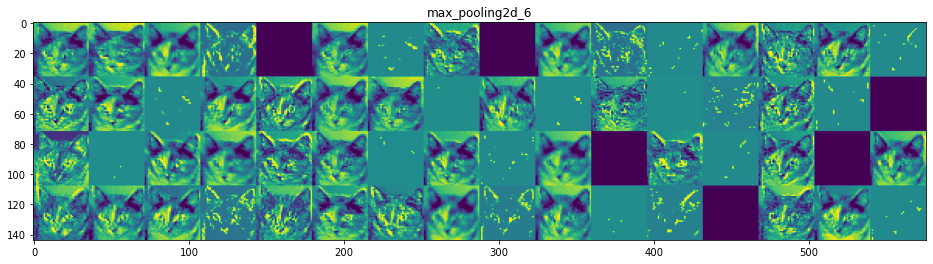

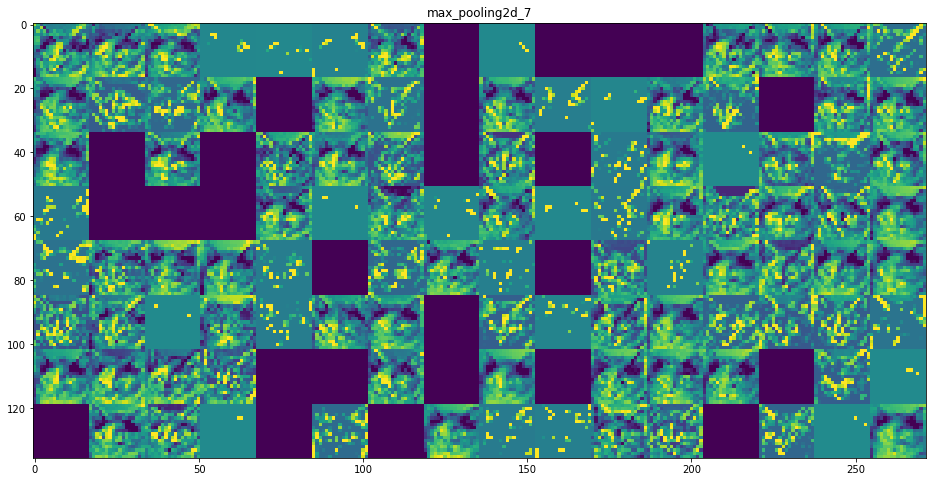
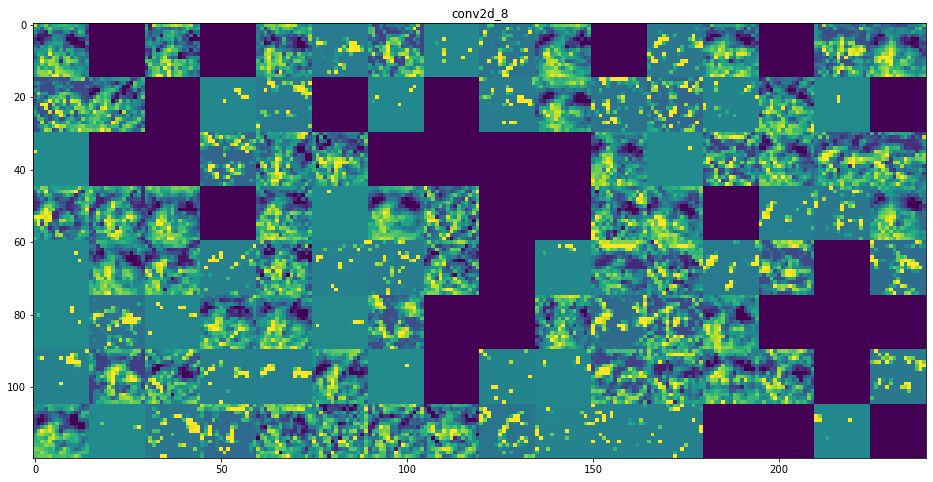
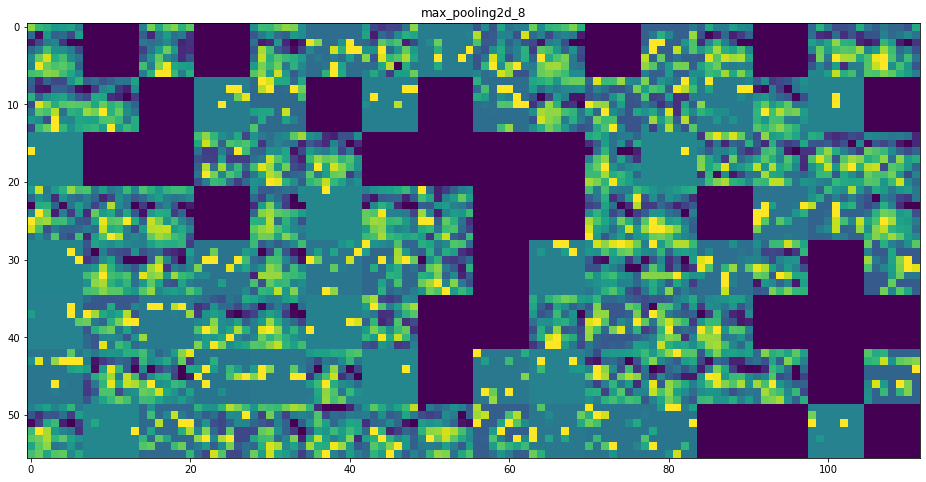
그림 5-27. 고양이 테스트 사진에서 각 층의 활성화 채널
결과로부터 몇 가지 주목할 내용이 있습니다.
- 첫 번째 층은 여러 종류의 에지 감지기를 모아 놓은 것 같습니다. 이 단계의 활성화에는 초기 사진에 있는 거의 모든 정보가 유지됩니다.
- 상위 층으로 갈수록 활성화는 점점 더 추상적으로 되고 시각적으로 이해하기 어려워집니다. ‘고양이 귀’와 ‘고양이 눈’처럼 고수준 개념을 인코딩하기 시작합니다. 상위 층의 표현은 이미지의 시각적 콘텐츠에 관한 정보가 점점 줄어들고 이미지의 클래스에 관한 정보가 점점 증가합니다.
- 활성화 되지 않은 필터들이 층이 깊어짐에 따라 늘어납니다. 활성화 되지 않다는 것은 필터에 인코딩된 패턴이 입력 이미지에 나타나지 않았다는 것을 의미합니다.
위 내용들로부터 심층 신경망이 학습한 표현에서 일반적으로 나타나는 중요한 특징들을 정리해 보겠습니다.
- 층에서 추출한 특성은 층의 깊이를 따라 점점 더 추상적이 됩니다.
- 높은 층의 활성화는 특정 입력에 관한 시각적 정보가 점점 줄어들고 타깃에 관한 정보(이 경우에는 강아지 또는 고양이 이미지의 클래스)가 점점 더 증가합니다.
- 심층 신경망은 입력되는 원본 데이터(여기서는 RGB 포맷의 사진)에 대한 정보 정제 파이프라인처럼 작동합니다. 반복적인 변환을 통해 관계없는 정보(예를 들어 이미지에 있는 특정 요소)를 걸러 내고 유용한 정보는 강조되고 개선됩니다(여기에서는 이미지의 클래스).
사람이 세상을 인지하는 방식이 이와 비슷합니다. 몇 초 동안 한 장면을 보고 난 후 장면의 추상적인 물체(자전거, 나무)를 기억할 순 있지만 구체적인 모양을 기억하지는 못합니다. 우리 뇌는 시각적 입력에서 관련성이 적은 요소를 필터링하여 고수준 개념으로 변환합니다. 이렇게 완전히 추상적으로 학습하기 때문에 눈으로 본 것을 자세히 기억하기는 매우 어렵습니다.

그림 5-28, 왼쪽: 기억에 의존하여 자전거 그리기. 오른쪽: 실제 자전거 모습
5.4.2 컨브넷 필터 시각화
이 방법은 각 필터가 반응하는 시각적 패턴을 그려보는 것입니다. 빈 입력 이미지에서 시작해서 특정 필터의 응답을 최대화하기 위해 컨브넷 입력 이미지에 경사 상승법3을 적용합니다. 결과적으로 입력 이미지는 선택된 필터가 최대로 응답하는 이미지가 될 것입니다.
전체 과정은 간단합니다.
- 특정 합성곱 층의 한 필터의 값을 최대화하는 손실 함수를 정의합니다.
- 이 활성화 값을 최대화하기 위해 입력 이미지를 변경하도록 확률적 경사 상승법을 사용합니다.
예를 들어 여기에서는사전 훈련된 VGG16 네트워크에서 block3_conv1 층의 필터 0번의 활성화를 손실로 정의합니다:
# 코드 5-32. 필터 시각화를 위한 손실 텐서 정의하기
from keras.applications import VGG16
from keras import backend as K
model = VGG16(weights='imagenet',
include_top=False)
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
경사 상승법을 구현하기 위해 모델의 입력에 대한 손실의 그래디언트가 필요합니다. 이를 위해 케라스의 backend 모듈에 있는 gradients 함수를 사용하겠습니다.
# 코드 5-33. 입력에 대한 손실의 그래디언트 구하기
# gradients 함수가 반환하는 텐서 리스트(여기에서는 크기가 1인 리스트)에서 첫 번째 텐서를 추출합니다
grads = K.gradients(loss, model.input)[0]
경사 상승법 과정을 부드럽게 하기 위해 사용하는 한 가지 기법은 그래디언트 텐서를 L2 노름(텐서에 있는 값을 제곱합의 제곱근)으로 나누어 정규화하는 것입니다. 이렇게 하면 입력 이미지에 적용할 수정량의 크기를 항상 일정 범위 안에 놓을 수 있습니다. 4
# 코드 5-34 그래디언트 정규화하기
# 0 나눗셈을 방지하기 위해 1e–5을 더합니다
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
이제 주어진 입력 이미지에 대해 손실 텐서와 그래디언트 텐서를 계산해야 합니다. 케라스 백엔드 함수를 사용하여 처리하겠습니다.5 iterate는 넘파이 텐서(크기가 1인 텐서의 리스트)를 입력으로 받아 손실과 그래디언트 두 개의 넘파이 텐서를 반환합니다.
# 코드 5-35 입력 값에 대한 넘파이 출력 값 추출하기
iterate = K.function([model.input], [loss, grads])
# 테스트:
import numpy as np
loss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])
여기에서 파이썬 루프를 만들어 확률적 경사 상승법을 구성합니다.
# 코드 5-36 확률적 경사 상승법을 사용한 손실 최대화하기
# 잡음이 섞인 회색 이미지로 시작합니다
input_img_data = np.random.random((1, 150, 150, 3)) * 20 + 128.
# 업데이트할 그래디언트의 크기
step = 1.
for i in range(40): # 경사 상승법을 40회 실행합니다
# 손실과 그래디언트를 계산합니다
loss_value, grads_value = iterate([input_img_data])
# 손실을 최대화하는 방향으로 입력 이미지를 수정합니다
input_img_data += grads_value * step
결과 이미지 텐서는 (1, 150, 150, 3) 크기의 부동 소수 텐서입니다. 이 텐서의 값은 [0, 255] 사이의 정수가 아닙니다. 따라서 출력 가능한 이미지로 변경하기 위해 후처리할 필요가 있습니다. 이를 위해 간단한 함수를 정의해 사용하겠습니다.
# 코드 5-37 텐서를 이미지 형태로 변환하기 위한 유틸리티 함수
def deprocess_image(x):
# 텐서의 평균이 0, 표준 편차가 0.1이 되도록 정규화합니다
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
# [0, 1]로 클리핑합니다
x += 0.5
x = np.clip(x, 0, 1)
# RGB 배열로 변환합니다
x *= 255
x = np.clip(x, 0, 255).astype('uint8')
return x
이 코드를 모아서 층의 이름과 필터 번호를 입력으로 받는 함수를 만들겠습니다. 이 함수는 필터 활성화를 최대화하는 패턴을 이미지 텐서로 출력합니다.
# 코드 5-38 필터 시각화 이미지를 만드는 함수
def generate_pattern(layer_name, filter_index, size=150):
# 주어진 층과 필터의 활성화를 최대화하기 위한 손실 함수를 정의합니다
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
# 손실에 대한 입력 이미지의 그래디언트를 계산합니다
grads = K.gradients(loss, model.input)[0]
# 그래디언트 정규화
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
# 입력 이미지에 대한 손실과 그래디언트를 반환합니다
iterate = K.function([model.input], [loss, grads])
# 잡음이 섞인 회색 이미지로 시작합니다
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
# 경사 상승법을 40 단계 실행합니다
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)
이 함수를 실행해 보죠(그림 5-29 참고).
plt.imshow(generate_pattern('block3_conv1', 0))
plt.show()

block3_conv1 층의 필터 0은 물방울 패턴에 반응하는 것 같습니다.
이제 재미있는 것을 만들어 보죠. 모든 층에 있는 필터를 시각화해보겠습니다. 간단하게 만들기 위해 각 층에서 처음 64개의 필터만 사용하겠습니다. 또 각 합성곱 블럭의 첫 번째 층만 살펴보겠습니다(block1_conv1, block2_conv1, block3_conv1, block4_conv1, block5_conv1). 여기서 얻은 출력을 64 × 64 필터 패턴의 8 × 8 그리드로 정렬합니다. 각 필터 패턴 사이에 검은 색 마진을 약간 둡니다.
# 코드 5-39 층에 있는 각 필터에 반응하는 패턴 생성하기
for layer_name in ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1']:
size = 64
margin = 5
# 결과를 담을 빈 (검은) 이미지
results = np.zeros((8 * size + 7 * margin, 8 * size + 7 * margin, 3), dtype='uint8')
for i in range(8): # results 그리드의 행을 반복합니다
for j in range(8): # results 그리드의 열을 반복합니다
# layer_name에 있는 i + (j * 8)번째 필터에 대한 패턴 생성합니다
filter_img = generate_pattern(layer_name, i + (j * 8), size=size)
# results 그리드의 (i, j) 번째 위치에 저장합니다
horizontal_start = i * size + i * margin
horizontal_end = horizontal_start + size
vertical_start = j * size + j * margin
vertical_end = vertical_start + size
results[horizontal_start: horizontal_end, vertical_start: vertical_end, :] = filter_img
# results 그리드를 그립니다
plt.figure(figsize=(20, 20))
plt.imshow(results)
plt.show()
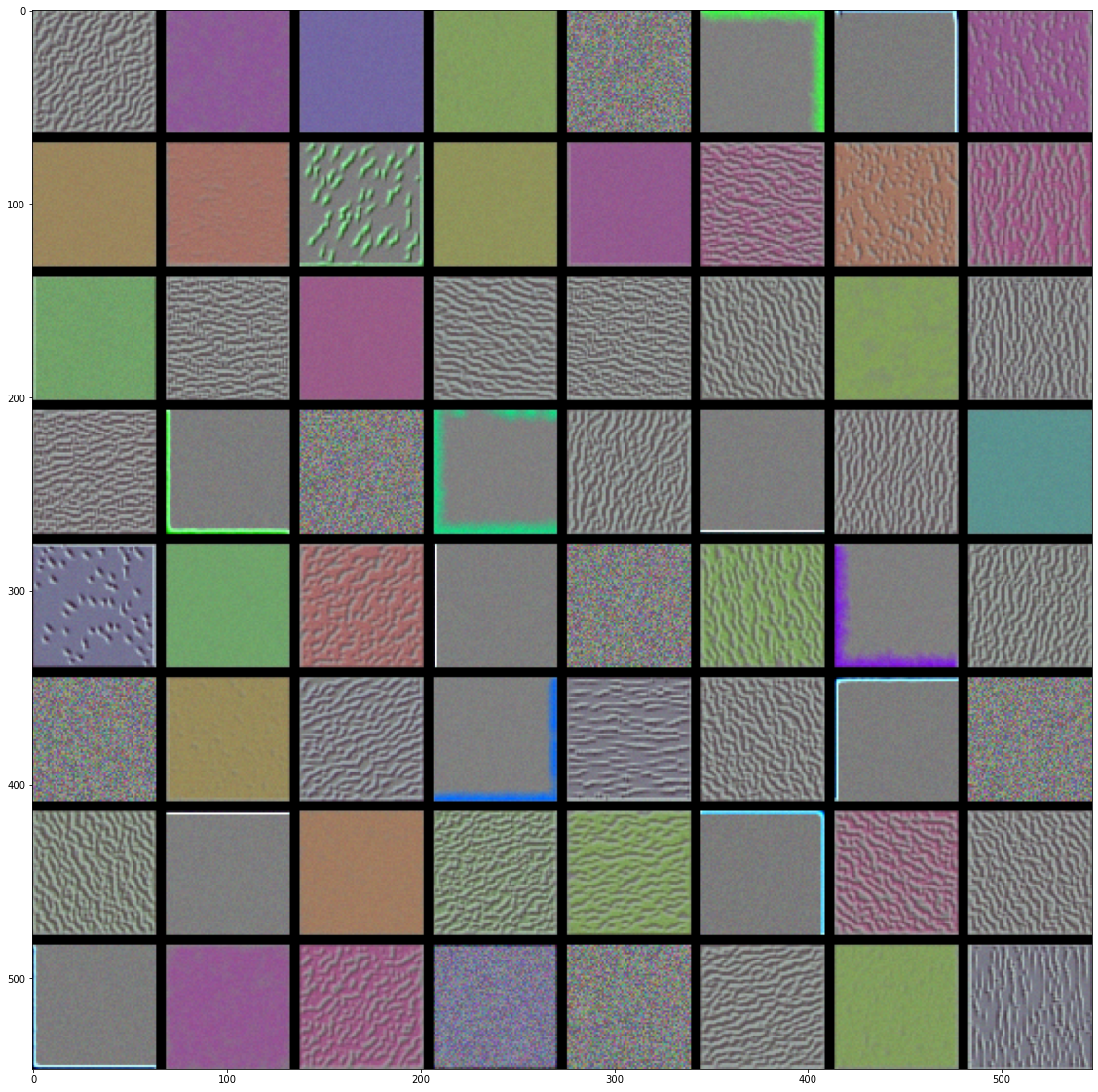
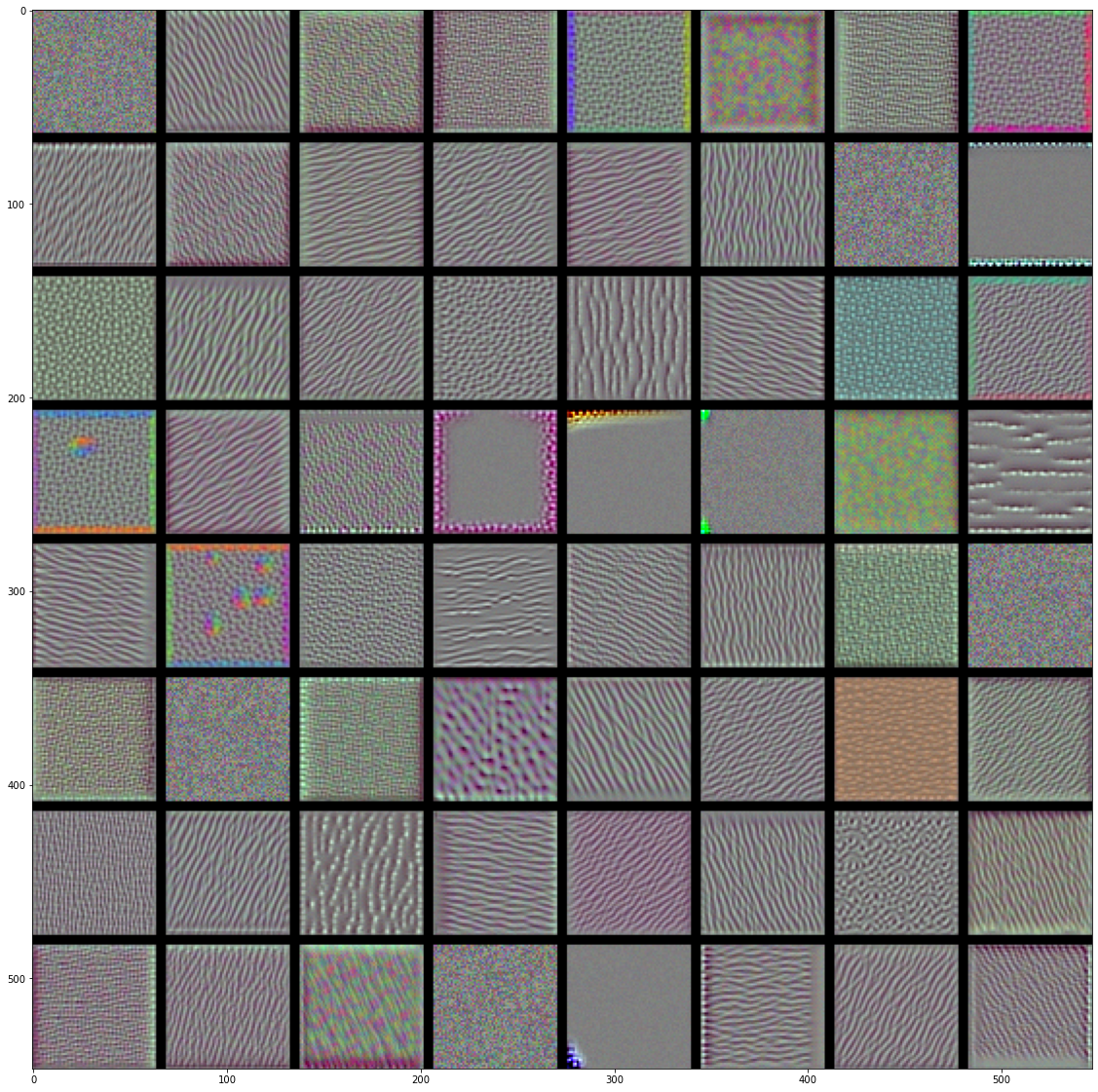
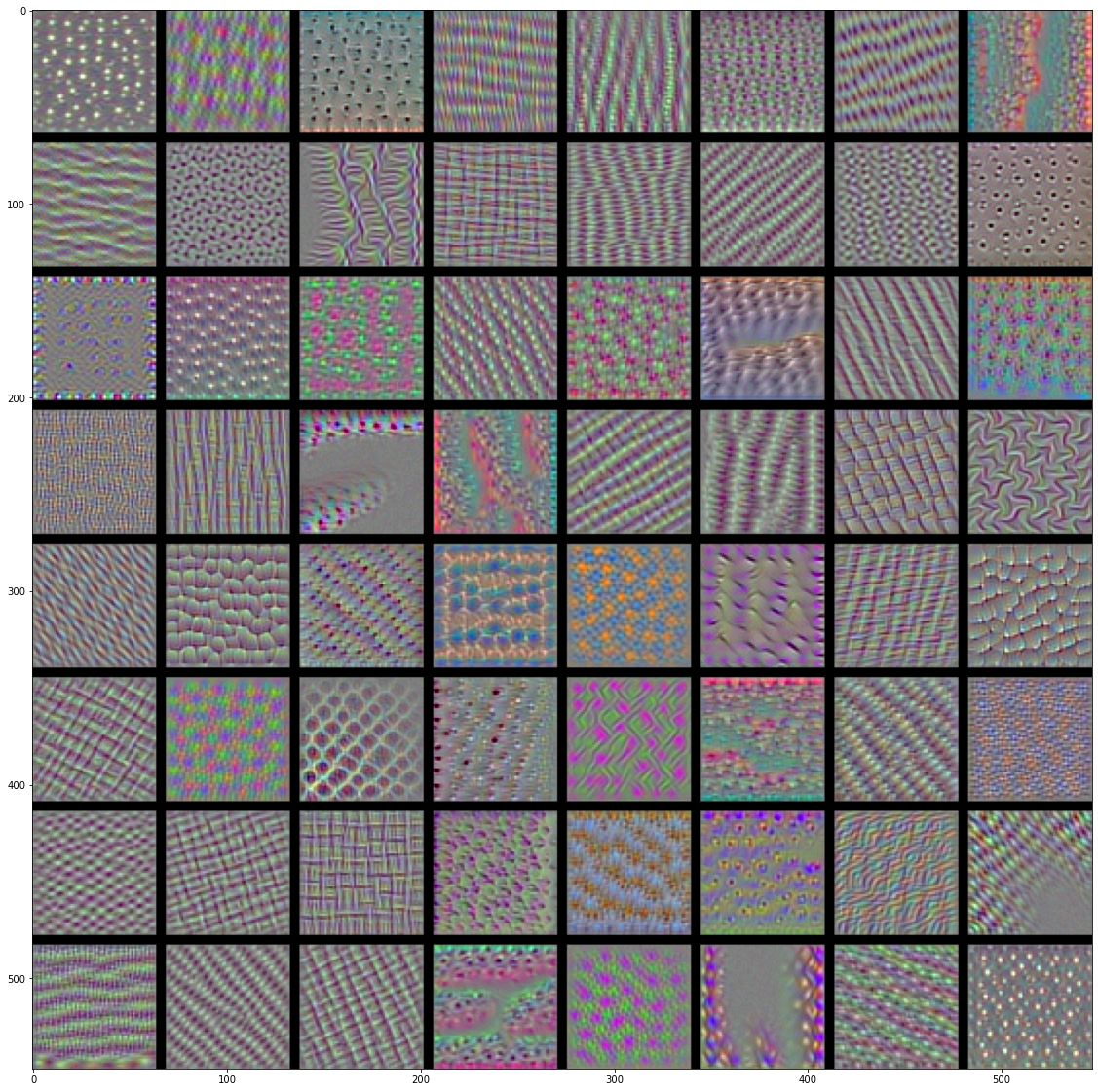
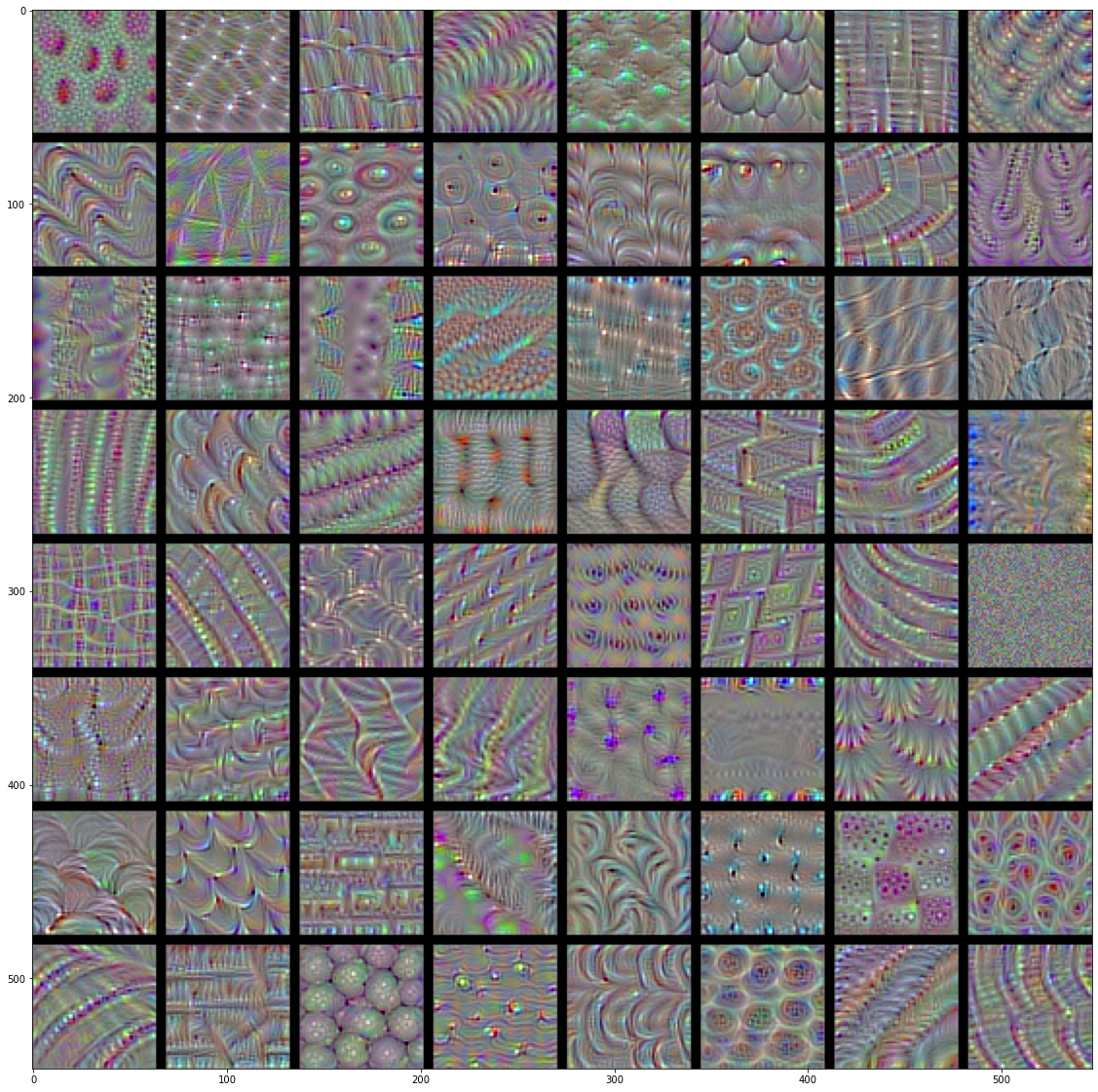
그림 5-30~33. block1_conv1~block4_conv1 층의 필터 패턴
이런 필터 시각화를 통해 컨브넷 층이 바라보는 방식을 이해할 수 있습니다. 컨브넷의 각 층은 필터의 조합으로 입력을 표현할 수 있는 일련의 필터를 학습합니다. 이는 푸리에 변환(Fourier transform)을 사용하여 신호를 일련의 코사인 함수로 분해할 수 있는 것과 비슷합니다. 이 컨브넷 필터들은 모델의 상위 층으로 갈수록 점점 더 복잡해지고 개선됩니다.
- 모델에 있는 첫 번째 층(
block1_conv1)의 필터는 간단한 대각선 방향의 에지와 색깔(또는 어떤 경우에 색깔이 있는 에지)을 인코딩합니다. block2_conv1의 필터는 에지나 색깔의 조합으로 만들어진 간단한 질감을 인코딩합니다.- 더 상위 층의 필터는 깃털, 눈, 나뭇잎 등과 같은 자연적인 이미지에서 찾을 수 있는 질감을 닮아가기 시작합니다.
5.4.3 클래스 활성화의 히트맵 시각화하기
이 방법은 이미지의 어느 부분이 컨브넷의 최종 분류 결정에 기여하는지 이해하는데 유용합니다. 분류에 실수가 있는 경우 컨브넷의 결정 과정을 디버깅하는 데 도움이 됩니다. 또 이미지에 특정 물체가 있는 위치를 파악하는 데 사용할 수도 있습니다.
이 기법의 종류를 일반적으로 클래스 활성화 맵(Class Activation Map, CAM) 시각화라고 부릅니다. 입력 이미지에 대한 클래스 활성화의 히트맵을 만들어 클래스에 대해 각 위치가 얼마나 중요한지 알려 줍니다. 예를 들어 강아지 vs. 고양이 컨브넷에 한 이미지를 주입하면 CAM 시각화는 고양이 클래스에 대한 히트맵을 생성하여 이미지에서 고양이와 비슷한 부분을 알려 줍니다.
여기서 사용할 구체적인 구현은 Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization7에 기술되어 있는 것입니다.
이 방법은 매우 간단합니다.
- 입력 이미지가 주어지면 합성곱 층에 있는 특성 맵의 출력을 추출
- 특성 맵의 모든 채널의 출력에 채널에 대한 클래스의 그래디언트 평균을 곱
이 기법을 직관적으로 이해하는 방법은 다음과 같습니다.
‘입력 이미지가 각 채널을 활성화하는 정도’에 대한 공간적인 맵을 ‘클래스에 대한 각 채널의 중요도’로 가중치를 부여하여 ‘입력 이미지가 클래스를 활성화하는 정도‘에 대한 공간적인 맵을 만드는 것입니다.
사전 훈련된 VGG16 네트워크를 다시 사용하여 이 기법을 시연해 보겠습니다:
# 코드 5-40 사전 훈련된 가중치로 VGG16 네트워크 로드하기
from keras.applications.vgg16 import VGG16
K.clear_session()
# 이전 모든 예제에서는 최상단의 완전 연결 분류기를 제외했지만 여기서는 포함합니다
model = VGG16(weights='imagenet')
그림 5-34에 있는 초원을 걷는 어미와 새끼 아프리카 코끼리의 이미지(크리에이티브 커먼즈(Creative Commons) 라이선스)를 적용해 보겠습니다.

그림 5-34. 아프리카 코끼리 사진
이 이미지를 VGG16 모델이 인식할 수 있도록 변환해 보죠. 이 모델은 224×224 크기의 이미지에서 훈련되었고 keras.applications.vgg16.preprocess_input 함수에 있는 몇 가지 규칙에 따라 전처리 되었습니다. 그러므로 이 이미지를 로드해서 224×224 크기로 변경하고 넘파이 float32 텐서로 바꾼 후 이 전처리 함수를 적용해야 합니다.
# 코드 5-41. VGG16을 위해 입력 이미지 전처리하기
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
# 이미지 경로
img_path = './datasets/creative_commons_elephant.jpg'
# 224 × 224 크기의 파이썬 이미징 라이브러리(PIL) 객체로 반환됩니다
img = image.load_img(img_path, target_size=(224, 224))
# (224, 224, 3) 크기의 넘파이 float32 배열
x = image.img_to_array(img)
# 차원을 추가하여 (1, 224, 224, 3) 크기의 배치로 배열을 변환합니다
x = np.expand_dims(x, axis=0)
# 데이터를 전처리합니다(채널별 컬러 정규화를 수행합니다)
x = preprocess_input(x)
이제 이 이미지에서 사전 훈련된 네트워크를 실행하고 예측 벡터를 이해하기 쉽게 디코딩합니다.9
preds = model.predict(x)
print('Predicted:', decode_predictions(preds, top=3)[0])
Predicted: [('n02504458', 'African_elephant', 0.90988606), ('n01871265', 'tusker', 0.08572466), ('n02504013', 'Indian_elephant', 0.0043471307)]
이 이미지에 대한 상위 세 개의 예측 클래스는 다음과 같습니다.
- 아프리카 코끼리 (92.5% 확률)
- 코끼리(tusker) (7% 확률)
- 인도 코끼리 (0.4% 확률)
네트워크는 이 이미지가 아프리카 코끼리를 담고 있다고 인식했습니다. 예측 벡터에서 최대로 활성화된 항목은 ‘아프리카 코끼리’ 클래스에 대한 것으로 386번 인덱스입니다:
np.argmax(preds[0])
386
이미지에서 가장 아프리카 코끼리 같은 부위를 시각화하기 위해 Grad-CAM 처리 과정을 구현하겠습니다.
# 코드 5-42. Grad-CAM 알고리즘 설정하기
# 예측 벡터의 '아프리카 코끼리' 항목
african_elephant_output = model.output[:, 386]
# VGG16의 마지막 합성곱 층인 block5_conv3 층의 특성 맵
last_conv_layer = model.get_layer('block5_conv3')
# block5_conv3의 특성 맵 출력에 대한 '아프리카 코끼리' 클래스의 그래디언트
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]
# 특성 맵 채널별 그래디언트 평균 값이 담긴 (512,) 크기의 벡터
pooled_grads = K.mean(grads, axis=(0, 1, 2))
# 샘플 이미지가 주어졌을 때 방금 전 정의한 pooled_grads와 block5_conv3의 특성 맵 출력을 구합니다
iterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])
# 두 마리 코끼리가 있는 샘플 이미지를 주입하고 두 개의 넘파이 배열을 얻습니다
pooled_grads_value, conv_layer_output_value = iterate([x])
# "아프리카 코끼리" 클래스에 대한 "채널의 중요도"를 특성 맵 배열의 채널에 곱합니다
for i in range(512):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
# 만들어진 특성 맵에서 채널 축을 따라 평균한 값이 클래스 활성화의 히트맵입니다
heatmap = np.mean(conv_layer_output_value, axis=-1)
시각화를 위해 히트맵을 [0, 1] 사이로 정규화하겠습니다. 최종 결과는 그림 5-35와 같습니다:
# 코드 5-43. 히트맵 후처리하기
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
plt.show()
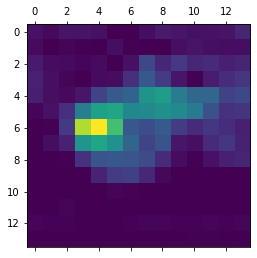
그림 5-35. 테스트 사진에 대한 아프리카 코끼리 클래스 활성화 히트맵10
마지막으로 OpenCV를 사용하여 앞에서 얻은 히트맵에 원본 이미지를 겹친 이미지를 만들겠습니다(그림 5-36 참고).
# 코드 5-44. 원본 이미지에 히트맵 덧붙이기
import cv2
# cv2 모듈을 사용해 원본 이미지를 로드합니다
img = cv2.imread(img_path)
# heatmap을 원본 이미지 크기에 맞게 변경합니다
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
# heatmap을 RGB 포맷으로 변환합니다
heatmap = np.uint8(255 * heatmap)
# 히트맵으로 변환합니다
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
# 0.4는 히트맵의 강도입니다
superimposed_img = heatmap * 0.4 + img
# 디스크에 이미지를 저장합니다
cv2.imwrite('./datasets/elephant_cam.jpg', superimposed_img)
True

그림 5-36 원본 이미지에 클래스 활성화 히트맵을 겹친 이미지
이 시각화 기법은 2개의 중요한 질문에 대한 답을 줍니다.
- 왜 네트워크가 이 이미지에 아프리카 코끼리가 있다고 생각하는가?
- 아프리카 코끼리가 사진 어디에 있는가?
특히 코끼리 새끼의 귀가 강하게 활성화된 점이 흥미롭습니다. 아마도 이것은 네트워크가 아프리카 코끼리와 인도 코끼리의 차이를 구분하는 방법일 것입니다.11
-
열을 뜻하는 히트와 지도를 뜻하는 맵을 결합시킨 단어로, 색상으로 표현할 수 있는 다양한 정보를 일정한 이미지위에 열분포 형태의 비쥬얼한 그래픽으로 출력하는 것이 특징이다 (위키백과). 히트맵에 사용하는 전형적인 컬러맵(colormap)은 파란색(낮은 값), 녹색, 빨간색(높은 값)을 사용하는 제트(jet) 컬러맵입니다. 코드 5-44에 있는
cv2.COLORMAP_JET가 제트 컬러맵을 의미합니다. ↩ -
입력 데이터의 첫 번째 차원은 배치 차원입니다. 데이터가 하나뿐이더라도 입력 데이터의 차원을 맞추어야 하므로 첫 번째 차원을 추가합니다. 코드 5-12에서는 같은 작업에
reshape()메서드를 사용했습니다. ↩ -
경사 상승법은 손실 함수의 값이 커지는 방향으로 그래디언트를 업데이트하기 때문에 경사 하강법과 반대이지만, 학습 과정은 동일합니다. 이 절에서는 두 용어를 섞어 사용하는데 번역서에서는 혼동을 피하기 위해 경사 상승법으로 통일했습니다. ↩
-
이런 기법을 그래디언트 클리핑(gradient clipping)이라고 합니다. L2 노름으로 나눈 그래디언트의 L2 노름은 1이 됩니다. 케라스의
keras.optimizers모듈 아래에 있는 옵티마이저를 사용할 때는clipnorm과clipvalue매개변수를 설정하여 자동으로 그래디언트 클리핑을 수행할 수 있습니다.clipnorm매개변수 값이 그래디언트의 L2 노름보다 클 경우 각 그래디언트의 L2 노름을clipnorm값으로 정규화합니다.clipvalue매개변수를 지정하면 그래디언트의 최대 절댓값은clipvalue값이 됩니다. 두 매개변수를 모두 설정하면clipnorm이 먼저 적용되고clipvalue가 적용됩니다. ↩ -
경사 상승법을 사용하기 때문에
keras.optimizers모듈 아래에 있는 옵티마이저를 사용할 수 없고, 직접 학습 단계를 구현해야 합니다.keras.backend.function()함수는 입력 값을 받아 지정된 출력 텐서들을 얻을 수 있는keras.backend.Function객체를 만들어 줍니다. ↩ -
코드 5-31에서 했던 것과 유사합니다. 여기에서는 표준 점수의 5배수 이내에 있는 값(거의 100%가 포함됩니다)들을 [0, 255] 사이로 압축했습니다. ↩
-
Ramprasaath R. Selvaraju et al., arXiv (2017), https://arxiv.org/abs/1610.02391. ↩
-
VGG 모델은 카페(Caffe) 딥러닝 라이브러리에서 훈련되어 정규화 방식이 조금 다릅니다. 입력 데이터의 이미지 채널을 RGB에서 BGR로 바꾸고 ImageNet 데이터셋에서 구한 채널별 평균값
[103.939, 116.779, 123.68]을 뺍니다. ↩ -
decode_predictions()함수는 ImageNet 데이터셋에 대한 예측 결과에서top매개변수에 지정된 수만큼 최상위 항목을 반환해 줍니다. ↩ -
matplotlib의 기본 컬러맵은viridis로 노란색이 가장 높은 값을 나타냅니다. ↩ -
인도 코끼리는 아프리카 코끼리보다 작은 귀를 가진 것이 특징입니다. 그림 5-36에서 아기 코끼리의 귀 부분이 붉게 표시되었습니다. ↩
댓글남기기