
이미지 분류 모델 평가에 사용되는 top-5 error와 top-1 error
원글: https://bskyvision.com/422
딥러닝 관련 논문을 보다보면 실험 평가 부분에서 top-5 error와 top-1 error라는 용어들을 심심찮게 발견하게 된다. top-5 error와 top-1 error는 이미지 분류(image classification) 성능을 평가하기 위한 것들이다.
훈련이 된 분류기(classifier)는 주어진 테스트 이미지가 어떤 클래스에 속하는지 분류해낼 것이다. {고양이, 강아지, 집, 축구공, 사자}와 같이 5개의 클래스 라벨을 가지고 훈련된 분류기가 있다고 가정해보자. 새로운 이미지를 이 분류기에 입력해줬는데, 0.1, 0.6, 0.05, 0.05, 0.2와 같은 결과를 냈다. 새로운 이미지가 강아지일 확률이 가장 높다고 판단한 것이다. 이때 top-1 class는 {강아지}가 된다. 그리고 top-2 class는 {강아지, 사자}가 된
분류기가 새로운 테스트 이미지들에 대해 예측한 클래스, 즉 top-1 class가 실제 클래스와 같다면 이때 top-1 error는 0%가 된다. 또한 분류기가 높은 확률로 예측한 상위 5개의 클래스, 즉 top-5 class 중에 실제 클래스가 있다면, 이때 top-5 error는 0%가 된다. 클래스가 5개밖에 없다면 top-5 error는 무조건 0%일 것이다. 하지만 보통 클래스는 그것보다 훨씬 많다. 100개일 때도 있고, 1000개일 때도 있다. 그 이상이 될 수도 있다.
1000개의 클래스로 훈련된 분류기의 top-5 error가 5%보다 작으면, 분류 능력이 상당히 좋다고 판단할 수 있다. 클래스가 1000개 정도되면 가장 높은 확률로 판단한 다섯 개의 클래스는 서로 상당히 유사한 것들일 가능성이 크다. 모두 강아지인데 조금씩 생김새가 다른 품종일수도 있다. 따라서 top-5 error가 낮으면 분류기의 성능이 좋다고 판단할 수 있는 것이다.
Mean IU란?
IU는 Intersection over Union의 약자로 특정 색상에서의 실제 블록과 예측 블록 간의 합집합 영역 대비 교집합 영역의 비율입니다. MeanIU는 색상별로 구한 IU의 평균값을 취한 것입니다.
Mean IU = (녹색 블록 IU + 노란색 블록 IU) / 2
각 모델의 결과에 대해 Mean IU을 계산해보겠습니다.

Semantic Segmentaion이란?

분류(Classification) 이란 영상에서는 특정 대상이 있는지 확인하는 기술을 말하며, 위의 예에서 output으로 cat이 나오게 됩니다. 통상적으로 (convolution + polling) 네트워크 뒤에 FLC(Fully Connected Layer)가 오는 형태가 일반적이다. AlexNet, VGGNet, GoogLeNet 등이 여기에 속하며 거의 유명한 신경망들이 비슷한 구조를 갖는다. FCL을 거치면 위치나 공간에 관련된 정보는 모드 사라진다.
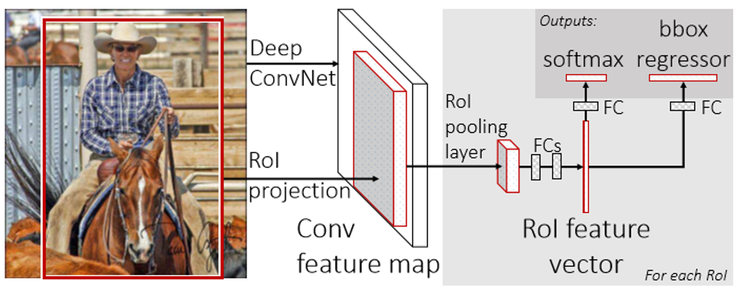
검출(Detection)은 분류(classification)와 달리 특정 대상이 있는지 여부만을 가리는 것이 아니라 위치정보도 포함한다. 보통은 바운딩 박스(bounding box)라 부르는 사각형의 영역을 통해 대상의 위치정보까지 포함한다. 검출은 class 여부를 가리는 softmax 부분과 위치정보를 구하는 bbox regressor 부분으로 구성된다. R-CNN, SPPNet, Fast R-CNN, Faster R-CNN등이 여기에 속한다. 추후 정리하겠다.
Sementic Segmentation은, 주어진 이미지 안에 어느 특정 클래스에 해당하는 사물이 (만약 있다면) 어느 위치에 포함되어 있는지 ‘픽셀 단위로’ 분할하는 모델을 만드는 것을 목표로 한다.
IoU란?
Intersection over Union의 약자로 Detection 경우 사물의 클래스 및 위치에 대한 예측 결과를 동시에 평가해야 하기 때문에 bounding box와 class가 이미지 레이블 상에 포함되어 있으며, 실제(ground truth)와 모델이 예측한 결과(prediction)간의 비교를 통해 평가한다.
즉, 정확도가 높다는 것은 모델이 ground truth와 유사한 bounding box와 box 안의 object의 class를 잘 예측(Classification)하는 것을 의미한다.
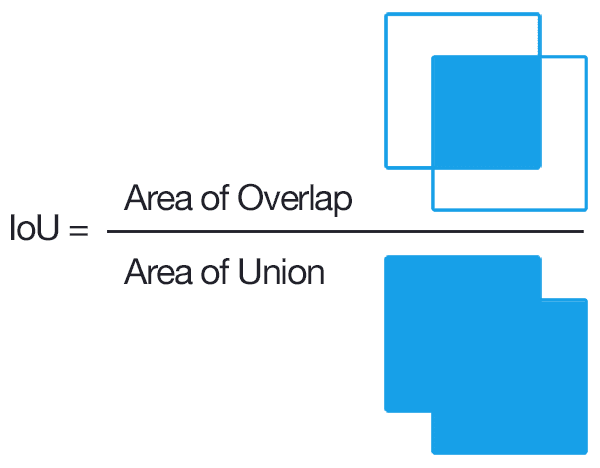
IoU는 교집합이 없는 경우에는 0을, ground truth와 prediction이 100% 일치하는 경우에는 1의 값을 가진다. 일반적으로 IoU가 0.5(threshold)를 넘으면 정답이라고 생각하며, 대표적인 데이터셋들마다 아래와 같이 다른 threshold를 사용한다.
- PASCAL VOC: 0.5
- ImageNet: min(0.5, wh/(w+10)(h+10))
- MS COCO: 0.5, 0.55, 0.6, .., 0.95
댓글남기기