
논문 링크 : https://arxiv.org/pdf/1409.4842.pdf
Abstract
본 논문은 ImageNet Large-Scale Visual Recognition Challenge 2014(ILSVRC14)에서 classification 및 detection를 위한 최점단 기술인 codename Inception이라 불리는 deep convolutional neural network 아키텍처를 제안한다.
이 아키텍처의 주요 특징은 네트워크 안에서 컴퓨팅 리소스의 활용을 향상시켰다는 점이다.
이는 컴퓨팅 예산은 일정하게 유지하면서, 네트워크의 깊이와 너비를 증가할 수 있도록 설계되었기 때문에 가능했다.
ILSVRC14에 제출되었던 모델은 22layers deep 네트워크인 GoogLeNet이라고하며, 분류 및 탐지 부분에서 평가된다.
1. Introduction
지난 3년간, 주로 deep learning의 발전. 좀더 구체적으로 convolutional 네트워크의 발전으로, 이미지 인식과 object detection은 드라마틱한 속도로 발전해왔다.
한 가지 소식은, 대부분의 발전은 더 강력해진 하드웨어, 더 커진 데이터, 더 큰 모델 뿐 아니라 주로 새로운 아이디어와 알고리즘, 향상된 네트워크 아키텍처의 결과라는 것이다.
또 다른 주목할만한 요소는 모바일 및 임베디드 컴퓨팅의 지속적인 관심으로 인해 알고리즘의 효율성, 특히 전력 및 메모리 사용이 중요하다는 것이다.
따라서 대부분의 실험에서 모델은 1.5억번의 연산을 넘지 않도록 설계했으며, 이는 단지 학술적인 호기심으로 끝날 것이 아니라, 실제에서도 사용하기 위함이다.
본 논문에서, 우리는 Inception(“we need to go deeper” 라는 유명한 인터넷 밈과 함께 Lin의 논문 Network-in-Network로부터 그 이름을 유래하였다.)이라는 computer vision에서 효율적인 deep neural network 아키텍처에 초점맞출 것이다.
우리의 상황에서, “deep”이라는 단어는 두 가지를 의미한다. AsAFWESCDVCVaz Rasdf QAWEQ 1.fdas “Inception module”의 형태a로sdf 새aafdd로운 수준의 조직을 도입한다는 의미 WQ E331sdsf3ZXCcZXzXCvzxcvzxcvzxcvxzcv2.afds 네트워크의 깊이를 늘린다는 의미
인셉션 모델은 Arora의 이론적 연구에서 영감과 지침을 얻으면서, Network-in-Network 모델의 논리적인 절정으로 볼 수 있다.
2. Related Work
LeNet-5에서 시작하여, convolutional neural network (CNN)은 일반적으로 표준구조를 가졌다. - 쌓여진 convolutional layers(선택적으로 contrast normalization과 max pooling이 따라온다.)에 하나 이상의 fully-connected layers가 따라오는 구조.
이 기본 구조를 변형한 모델들은 이미지 분류분야에 널리 사용되며, MNIST, CIFAR 및 InageNet 분류 첼린지에서 최고의 성과를 얻었다.
ImageNet과 같은 대용량 데이터에서 최근 트렌드는 dropout으로 overffiting을 막으면서, layer 수와 layer 사이즈를 늘리는 것이다.
max-pooling은 정확한 공간적 정보를 손실함에도 불구하고, AlexNet과 같은 convolutional network 아키텍처에서 localization, object detection, human pose estimation에 성공적으로 사용되었다.
task of image classfication and object detection

Network-in-Network는 신경망의 표현력을 높이기 위해 Lin et al.이 제안한 방식이다.
convolutional layers에 적용될 때, 이 방법은 1X1 convolutional layers가 추가적으로 적용되며, rectified linear activation(ReLU)가 뒤따른다.
본 논문에서 1X1 convolutions는 두 가지 목적을 가지고 있다.
- 컴퓨터 병목현상을 제거하기 위한 차원축소 모듈
- 네트워크 크기 제한
이를 통해 성능을 크게 저하시키지 않으면서, 네트워크의 depth와 width를 증가시킬 수 있다.
Note
병목현상이란?
전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상.
“병목”이라는 용어는 물이 병 밖으로 빠져나갈 때 병의 몸통보다 병의 목부분의 내부 지름이 좁아서 물이 상대적으로 천천히 쏟아지는 것에 비유.
Network-in-Network

3. Motivation and High Level Considerations
deep neural networks의 성능을 향상시키는 가장 간단한 방법은 크기를 늘리는 것이다.
- depth의 증가 : level의 수
- width의 증가 : 각 level의 unit 수
하지만, 이 간단한 솔루션에는 두 가지 단점이 있다.
- 크기가 커진다는 것은 일반적으로 더 많은 parameter를 의미하며 이는 특히, 학습 데이터 수가 적은 경우에 overfitting되기 쉽다.
특히, figure 1에서 알 수 있듯이, ImageNet과 같이 세밀한 범주(1000 class, ILSVRC subset)를 구분해야 하는 경우 고품질의 학습 데이터를 만드는 것은 심각한 병목현상이 될 수 있다.
- 네트워크의 크기를 늘리는 것은 컴퓨터 자원의 사용이 크게 증가한다. 컴퓨팅 자원은 유한하기 때문에, 네트워크의 사이즈를 늘리는 것보다 컴퓨팅 자원을 효율적으로 분배하는 것이 더 중요하다.

위 두 문제를 해결하기 위한 간단한 방법은 convolution안에서도 fully connected에서 sparsely connected 아키텍처로 변경하는 것이다.
하지만, 현재의 하드웨어는 sparse한 메트릭스 연산에는 비효율 적이다.
따라서, sparse 메트릭스를 효율적으로 계산하기 위해서는 상대적으로 밀도가 높은 하위 dense 메트릭스들로 컬러스터링 한다.
4. Architectural Details
Inception 아키텍처의 주요 아이디어는, convolutional vision network에서 최적의 local sparse structure를 구성하고, 어떻게 dense components로 구성할 수 있을지를 알아내는 것이다. 네트워크는 convolutional block들을 쌓아서 구성된다. 즉, 우리는 최적의 local construction을 찾고, 그것을 반복하면 된다.
즉, 네트워크의 크기를 무턱대고 늘리면 overffiting현상과 계산량이 크게 증가한다는 단점이 있기 때문에, 네트워크를 sparse하게 구성하여 크기를 증가시킨다.
단, sparse한 structure는 하드웨어 계산에서 비효율 적이기 때문에 sparse structure를 다시 dense한 component들로 구성한다. 현재 Inception 구조는 1X1, 3X3, 5X5로 제한했으며, 이는 필요에 의함이 아닌 편리함을 위한 결정이다. (figure 2(a))

하지만, 위 모듈의 가장 큰 문제는 5X5 convolution이라도 수많은 filter가 쌓인다면, 엄청나게 계산량이 많아진다. 따라서, 두 번째 아이디어는 1X1 convolution을 통한 차원축소이다. (figure 2(b)) 1X1 covolution은 3X3과 5X5 covolution 전에 사용하여 연산량을 감소시켰다.
1X1 covolution은 두 가지 목적이 있다.
- 차원축소
- rectified linear activation(ReLU) 포함

이 아키텍처의 주요 이점 중 하나는 연산량을 크게 늘리지 않으면서, 네트워크의 크기를 늘릴 수 있다는 점이다.
Note 1X1 convolution
- channel 조절을 통한 차원감소
- 차원감소로 인한 연산량 감소
- 비선형성 표현

c3<c2 일 때 차원축소의 기능이 있다.
또한, convolution에 ReLU activation function으로 비선형성을 증가시킬 수 있다.
5. GoogLeNet
GoogLeNet table 구조는 table 1에 기술되어 있다.

위 컬럼의 의미는 다음과 같습니다.
- Type : layer에 사용된 type
- patch size/stride : convolution/pooling시 사용된 filter size 및 stride
- output size : convolution/pooling/inception module 적용후 얻는 feature map의 size
- depth : convolution layer의 개수.
- #1x1 : 1x1 convolution후 얻은 feature map의 개수.
- reduced #3x3 : Inception module안에서 3x3 convolution전에 수행되는 1x1 convolution후 얻은 feature map의 개수.
- #3x3 : 3x3 convolution후 얻은 feature map의 개수.
- reduced #5x5 : Inception module안에서 5x5 convolution전에 수행되는 1x1 convolution후 얻은 feature map의 개수.
- #5x5 : 5x5 convolution후 얻은 feature map의 개수.
- pool/proj : Inception module안에서 3x3 map-pooling후 수행되는 1x1 convolution후 얻은 feature map의 개수.
- params : 해당 layer에서 사용된 free parameter 개수.
- ops : 연산의 수
다음은 GoogLeNet 전체 아키텍쳐입니다.

빨간색으로 표시된 부분은 Auxiliary classifier를 사용한 것인데, deep한 network에서 학습시 발생할 수 있는 vanishing gradient 이슈를 개선하도록 설계하였습니다. 실제 추론시에는 해당 부분은 삭제후 적용되며, 학습시에만 적용합니다. 아래와 같이 layer가 구성됩니다. Auxiliary classifier loss에 0.3 weight를 적용 후, 최종적으로 Total loss에 더합니다. (Regularization 효과)
- average pooling 5x5 filter size/stride 3 적용, (4a) stage output 4x4x512 (4d) stage output 4x4x528
- 1x1 convolution /w 128 filters 적용
- fully-connected layer /w 1024 unit/ ReLU 적용
- dropout 70% ratio 적용
참고사항
GoogLeNet의 마지막 부분. 일반적으로 FC layer를 사용해서, 파라미터가 밀집되는 구역인데, Inception 모듈 뒤에 average pooling, FC layer, softmax를 사용함으로써 파라미터를 많이 줄였다.
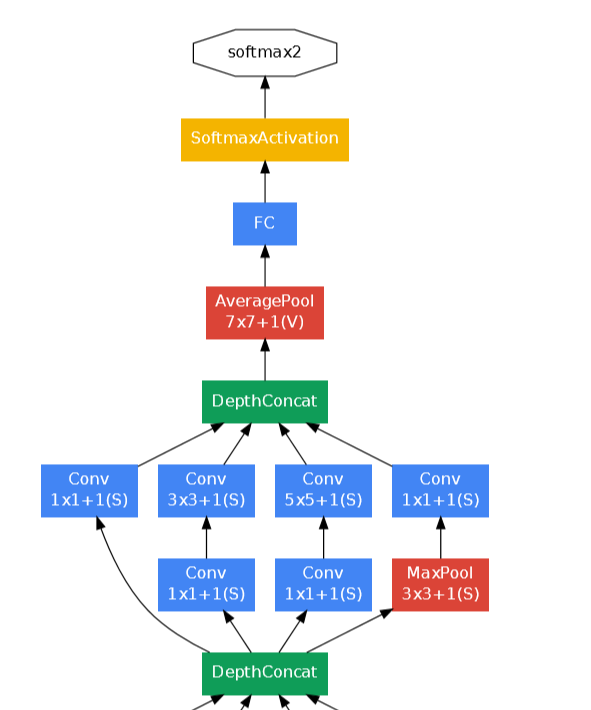
softmax layer는 총 3개가 있고 마지막 layer가 진짜이고 오른쪽 2개는 보조 softmax 레이어이다. 위 전체 아키텍쳐에서 오른쪽에 빨간색으로 표시해놓은 부분은 auxilary classifier(보조 분류기)이다.
6. Training Methodology
영상의 가로/세로 비를 [3/4, 4/3]의 범위를 유지하면서 원영상의 8%부터 100%까지 포함할 수 있도록 하여 다양한 크기의 patch를 학습에 사용하였다. 또한 photometric distortion을 통해 학습 데이타를 늘렸다.
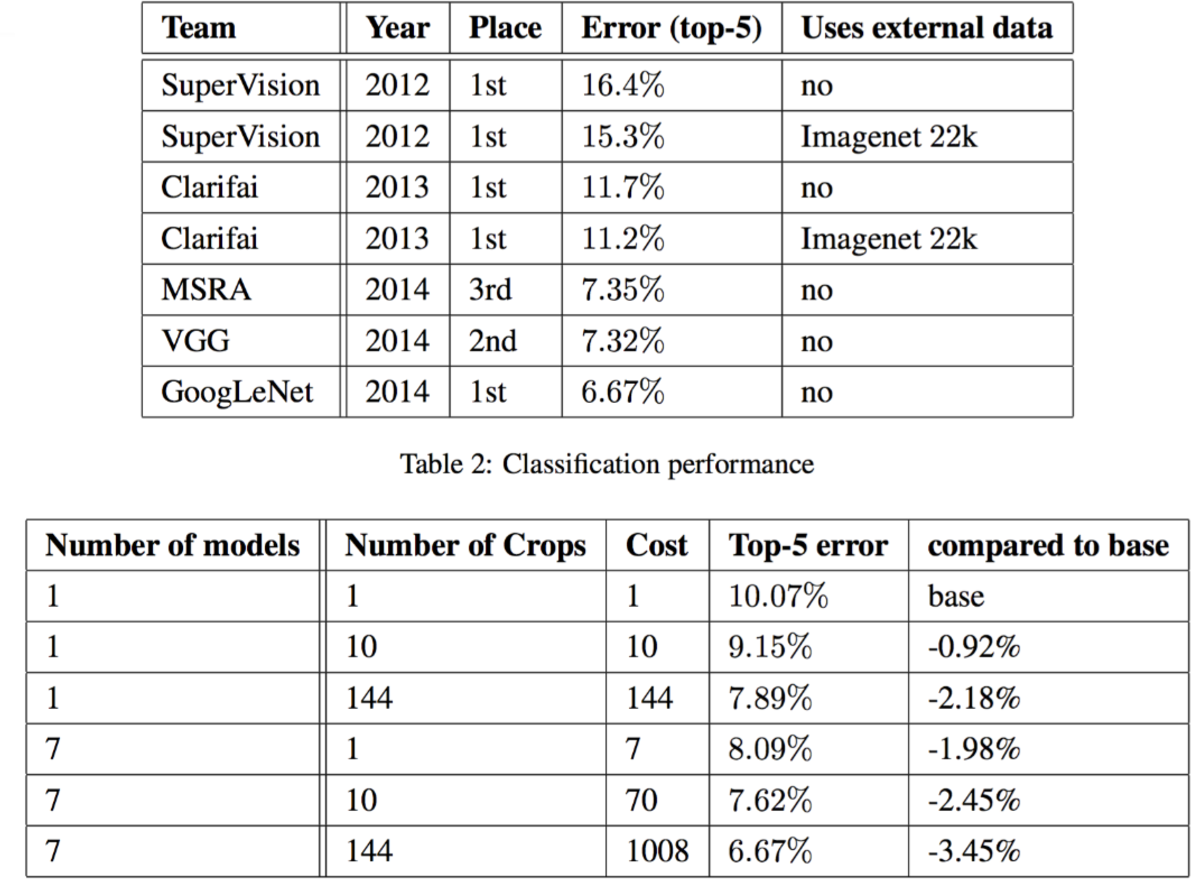
7. ILSVRC 2014 Classification Challenge Setup and Results
8. ILSVRC 2014 Detection Challenge Setup and Results
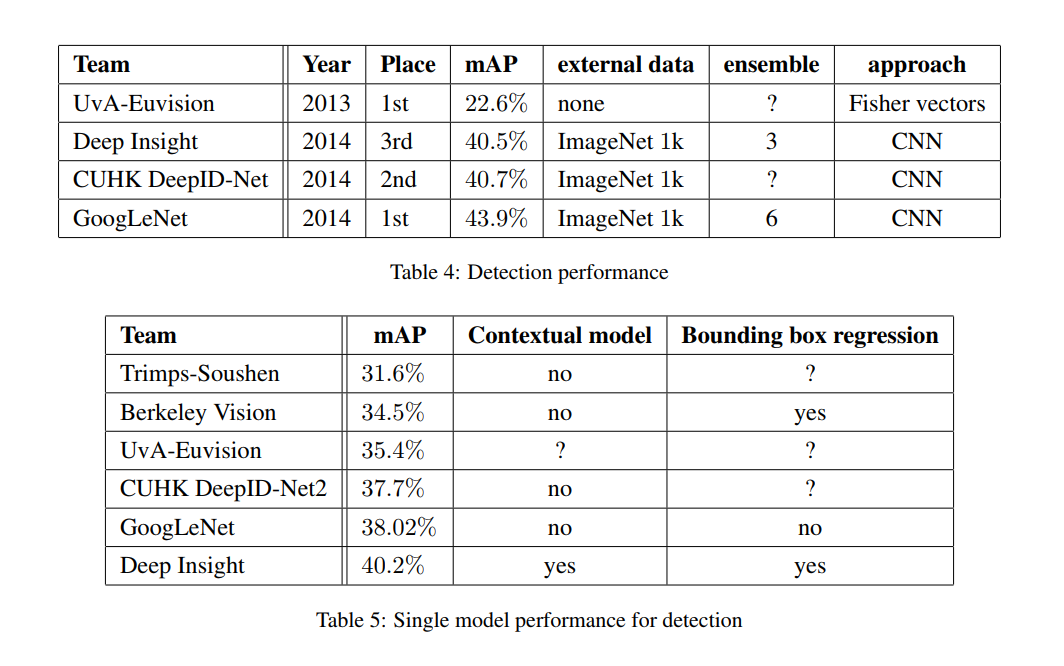
생략
9. Conclusion
- 이 눈문의 결과는 optimal sparse structure를 dense building block을 이용해서 근사한 것의 증거처럼 보인다.
- 이 방법의 메인 장점은 계산량이 조금 증가하는 것에 비해, 성능이 아주 좋아진다는 것이다.
- 이러한 접근이 sparser architecture가 실현가능하고, 유용하다는 증거가 된다.
Reference
댓글남기기