
논문 링크 : https://arxiv.org/pdf/1411.4038.pdf
Abstract
이 논문에서는 convolutional networks를 이용해 Semantic Segmentation 문제를 해결하고자 하였고, 좋은 성능을 얻었다. [PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012)]
Semantic Segmentation 모델을 위해 기존에 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)들을 목적에 맞춰 변형시켜 이용한다. 별다른 어려운 기법을 사용하지 않았음에도 Semantic Segmentation에서 뛰어난 성능을 보이며 2년도 안되는 기간동안 약 1300회 정도 인용되었다고 한다.
Note Mean IU란?
IU는 Intersection over Union의 약자로 특정 색상에서의 실제 블록과 예측 블록 간의 합집합 영역 대비 교집합 영역의 비율입니다. MeanIU는 색상별로 구한 IU의 평균값을 취한 것입니다.
Mean IU = (녹색 블록 IU + 노란색 블록 IU) / 2
각 모델의 결과에 대해 Mean IU을 계산해보겠습니다.

1. Introduction
Convolutional networks는 특징들(features)의 계층구조(hierarchies)를 시각화하기에 좋은 모델로 인식(recognition), 분류(classification), 바운딩 박스 물체 인식(bounding box object detection), 부분 및 키포인트 예측(part and keypoint prediction), 지역 대응(local correspondence)에서 강점을 갖는다.
FCN은 Semantic Segmentation 모델을 위해 기존에 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을 목적에 맞춰 변형시켰다.
Note Semantic Segmentaion이란?

분류(Classification) 이란 영상에서는 특정 대상이 있는지 확인하는 기술을 말하며, 위의 예에서 output으로 cat이 나오게 됩니다. 통상적으로 (convolution + polling) 네트워크 뒤에 FLC(Fully Connected Layer)가 오는 형태가 일반적이다. AlexNet, VGGNet, GoogLeNet 등이 여기에 속하며 거의 유명한 신경망들이 비슷한 구조를 갖는다. FCL을 거치면 위치나 공간에 관련된 정보는 모드 사라진다.
검출(Detection)은 분류(classification)와 달리 특정 대상이 있는지 여부만을 가리는 것이 아니라 위치정보도 포함한다. 보통은 바운딩 박스(bounding box)라 부르는 사각형의 영역을 통해 대상의 위치정보까지 포함한다. 검출은 class 여부를 가리는 softmax 부분과 위치정보를 구하는 bbox regressor 부분으로 구성된다. R-CNN, SPPNet, Fast R-CNN, Faster R-CNN등이 여기에 속한다. 추후 정리하겠다.
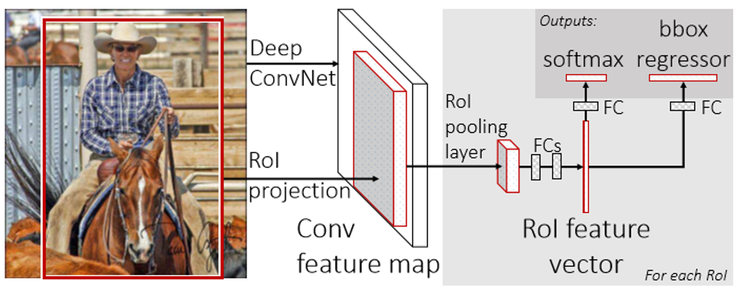
Sementic Segmentation은, 주어진 이미지 안에 어느 특정 클래스에 해당하는 사물이 (만약 있다면) 어느 위치에 포함되어 있는지 ‘픽셀 단위로’ 분할하는 모델을 만드는 것을 목표로 한다.
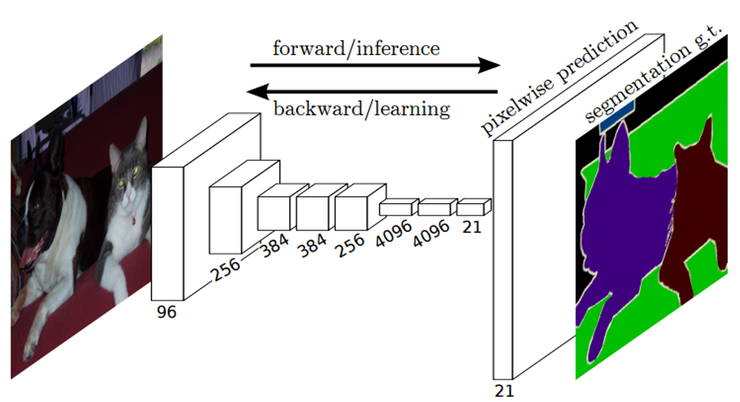
기존 분류 모델의 FCN화를 통해 임의의 크기 이미지에 대해 처리가 가능해 졌으며, patch를 사용하지 않아 등을 한번에 전체 이미지에 대해 빠르게 수행한다. 또한 네트워크내에 있는 업샘플링 계층(upsampling layer)은 하위 샘플링 풀링(subsampling pooling)을 통해 픽셀 단위 예측(pixelwise prediction) 및 학습을 가능하게 하였다.
FCN은 훈련의 효율성을 위해 패치(patch)를 사용하지 않았으며, pre- 및 post-processing complications등을 사용하지 않는다. 단지 분류에 좋은 성능을 보인 net들을 FCN화 및 fine-tuning하여 예측(prediction)에 적합하도록 하였다.
이러한 변형은 다음과 같이 세 과정으로 나타낼 수 있다.
- Convolutionalization
- Deconvolution (Upsampling)
- Skip architecture (skip-connection)
Semantic segmentation은 영상속에 무엇(what)이 있는지를 확인하는 것(semantic)뿐만 아니라 어느 위치(where)에 있는지(location)까지 정확하게 파악을 해줘야 한다. 하지만 semantic의 local한 성질이 짙은 반면 location은 global한 성질로 지향하는 바가 달라 이를 조화롭게 해결해야 한다. FCN 팀은 deep과 coarse의 조합, 즉 deep feature hierarchies를 위해 skip-architecture(skip-connection)를 정의하였다.
2. Related work
생략
Convolutionalization
3. Fully convolutional networks
본 논문에서 패치를 사용하지 않는 이유에 대해 아래와 같이 기술한다.
If the loss function is a sum over the spatial dimensions of the final layer, its gradient(l) will be a sum over the gradients (l’)of each of its spatial components. Thus stochastic gradient descent on l computed on whole images will be the same as stochastic gradient descent on l’, taking all of the final layer receptive fields as a minibatch. When these receptive fields overlap significantly, both feedforward computation and backpropagation are much more efficient when computed layer-by-layer over an entire image instead of independently patch-by-patch.
–> 손실 함수가 최종 계층의 공간 차원에 대한 합인 경우, gradient는 각 공간 요소에 대한 gradient들의 합과 같다. 따라서 이미지 전체 SGD는 각 공간 요소에 대한 SGD와 같고, 최종 계층의 receptive filed를 minibatch로 사용한다. 이 때 receptive field가 유의하게 겹칠 때(overlap significantly) feedforward computation 및 backpropagation이 패치 별로가 아닌 전체 이미지에 대해 계층별로 계산할 때 더 효과적이다.
3.2절에서는 분류를 위한 net들을 FCN으로 변환하기 위한 과정을 OverFeat과 함께 설명한다. 3.3절에서는 upsampling을 위한 deconvolution을 설명한다. 3.4절에서는 patchwise sampling에 의한 훈련을 살펴보고 4.3절에서 본 논문에서 제안하는 방법인 전체 이미지에 대한 훈련이 더 빠르고 효과적임을 보인다.
3.1. Adapting classifiers for dense prediction
기존의 유명한 분류 모델들은 ConvNet을 이용하여 영상의 특징(feature)들을 추출하고 class 분류를 위해 네트워크의 뒷단에 FCL(Fully Connected Layer)를 사용하게 된다.
그러나 FCL은 다음과 같은 이유로 image segmentation에 적합하지 않다.
-
FCL을 사용하기 위해서는 고정된 크기의 input만을 받아야 한다.
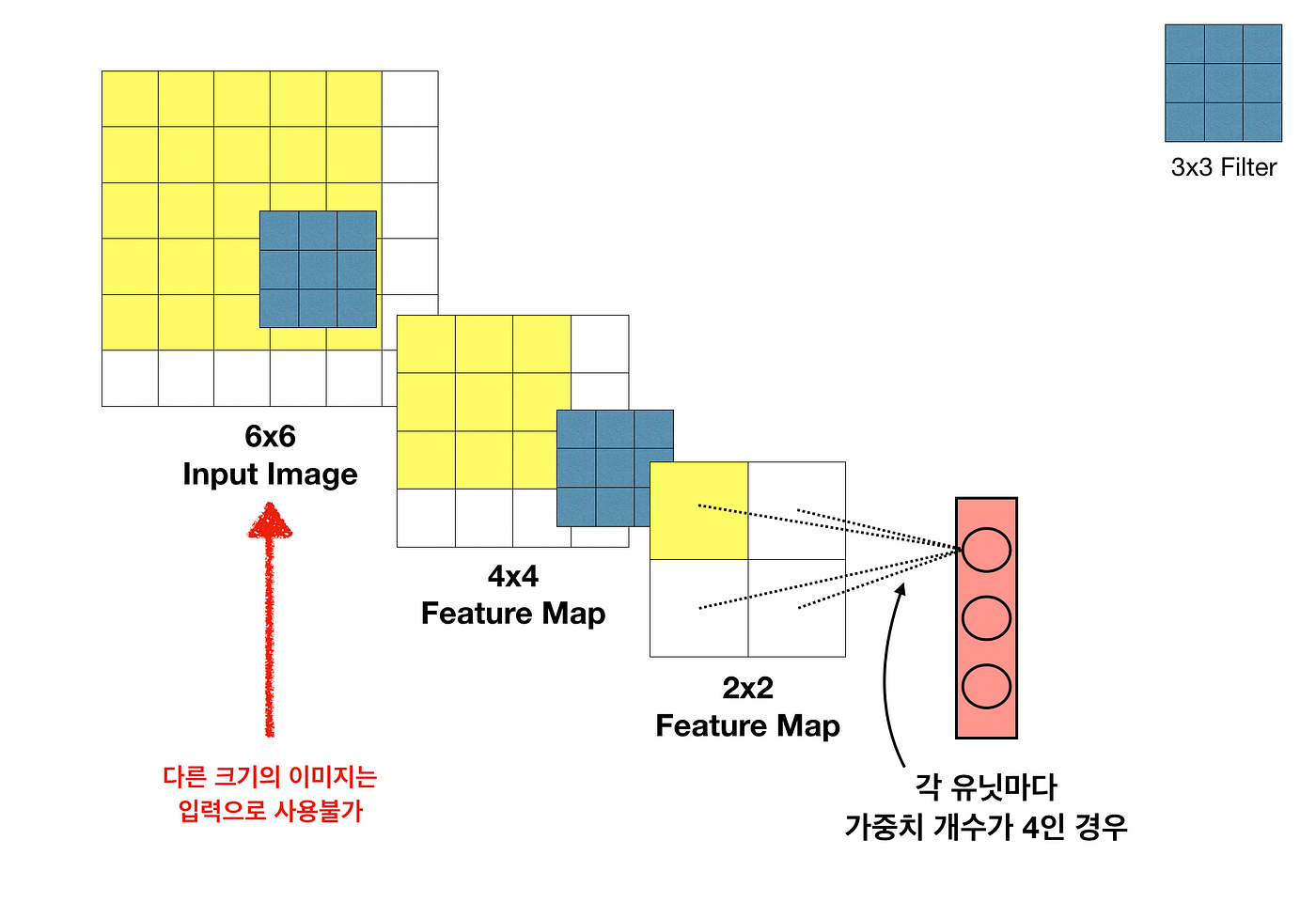
Dense layer에 가중치 개수가 고정되어 있기 때문에 바로 앞 레이어의 Feature Map의 크기도 고정되며, 연쇄적으로 각 레이어의 Feature Map 크기와 Input Image 크기 역시 고정된다. -
FCL을 거치고 나면 위치 정보 또한 사라진다.
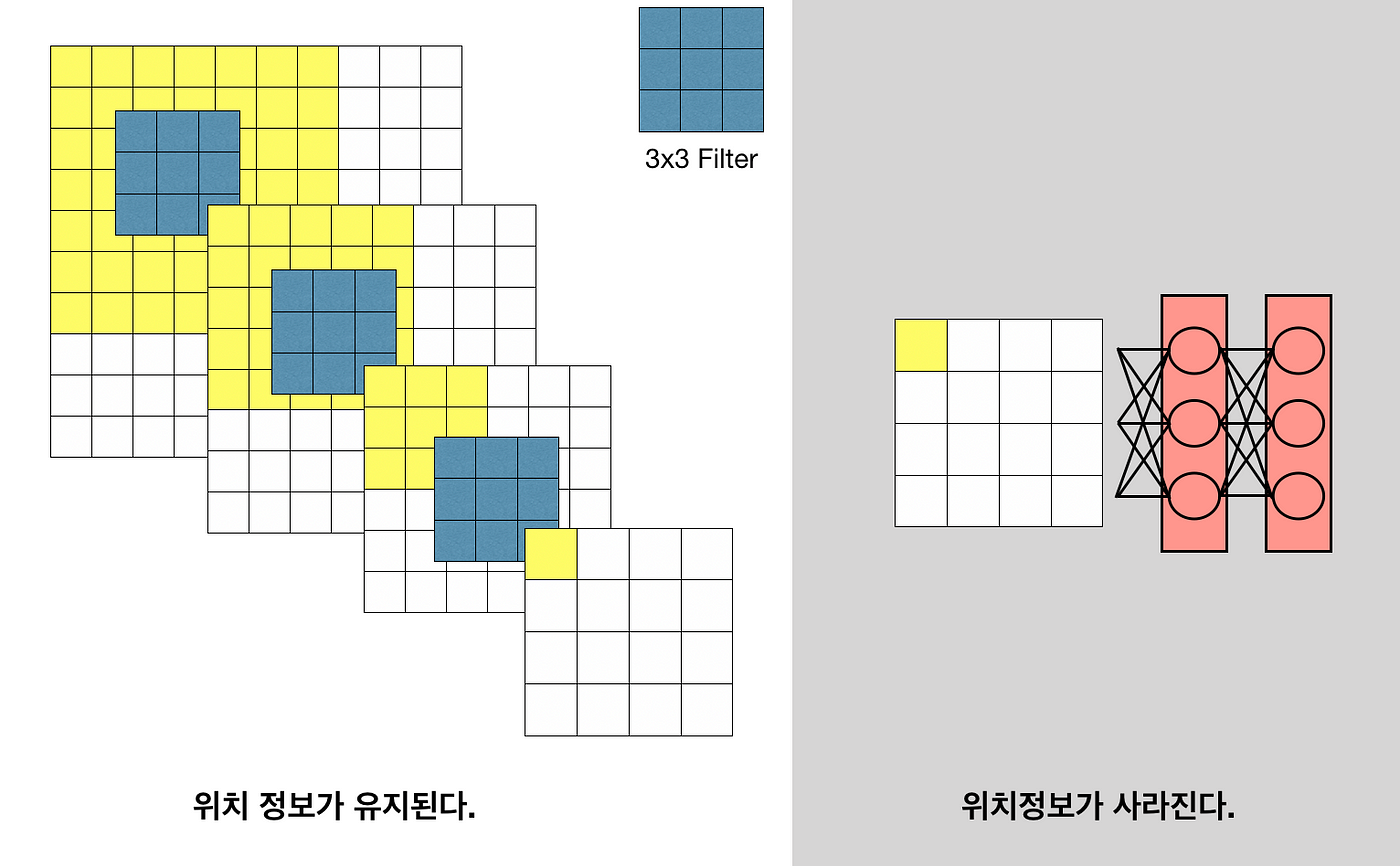
fully-connected layer 연산 이후 Receptive field 개념이 사라진다.
FCN에서는 위 단점을 보완하기 위해 뒷단의 FCL을 모두 convolution layer로 대체 하고자 하였다.

위 그림에서 보듯이 기존의 분류 모델의 뒷단 FCL을 convolution layer 정확하게는 1x1 conv로 바꾸었다.(본 논문에서는 이러한 과정을 Convolutionalization이라 한다.) 이 과정에서 얻는 이점은 아래과 같이 다시 정리해 볼 수 있다.
- 위치 정보 유지
- 입력 영상 크기에 대한 제한 없음 +. 추가적으로 patch 단위 처리가 아닌 전체 영상에 대해 한번에 처리하기 때문에 겹치는 영역에 대한 연산 낭비가 없어 속도에 대한 이점도 있다.
3.2. Shift-and-stitch is filter rarefaction
본 논문에서는 input에 대한 shift나 output에 대한 stitch는 어떠한 보간 없이 coarse한 output에 대해 dense하게 예측하기 위해 OverFeat에 의해 도입된 하나의 trick이라고 한다. 그러나 이 trick의 full net output을 재현하기 위해서는 계층별로 subsampling이 제거될 때까지 filter enlargement를 반복해야한다. Semantic segmentation을 위해서는 이 full net output 재현이 필요하다.
그렇다고 net에서의 subsampling 감소는 필터가 finer information을 볼 수 있도록 하지만 더 작은 receptive field로 인해 연산 시간이 오래 걸는 tradeoff 관계에 있다. 마찬가지로 shift-and-stitch는 receptive filed의 감소 없이 output을 더욱 dense하게 할 수는 있지만 output이 갖는 정보는 원본대비 줄어든다. 따라서 FCN 팀에서는 shift-and-stich 기법을 사용하지 않고 upsampling 및 skip-connection을 통한 학습으로 더 좋은 성능이 나옴을 보였다.
3.3. Upsampling is backwards strided convolution
ConvNet을 거치며 feature-map은 크기가 줄어들고, 픽셀 단위 dense하기 예측하기 위해서는 이 줄어든 feature-map을 아래와 같이 다시 키워야 한다.
가장 간단한 방법은 bilinear interpolation을 사용하면 된다. 하지만 end-to-end 학습의 관점에서는 고정된 값을 사용하는 것이 아니라 학습을 통해서 결정하는 편이 좋다. 논문에서는 backward convolution, 즉 deconvolution을 사용하며, deconvolution에 사용하는 필터의 계수는 학습을 통해서 결정이 되도록 하였다. 이렇게 되면, 경우에 따라서 bilinear 한 필터를 학습할 수도 있고 non-linear upsampling도 가능하게 된다.
단순하게 score를 upsampling하게 되면, 어느 정도 이상의 성능을 기대하기가 어렵다. 그래서 FCN팀은 아래 그림과 같이 skip-connection 개념을 활용하여 성능을 끌어올렸다.
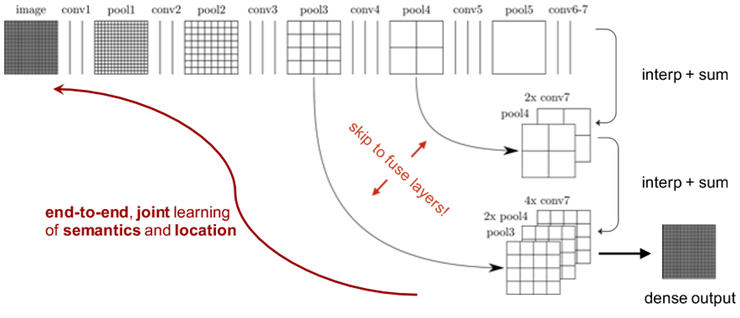
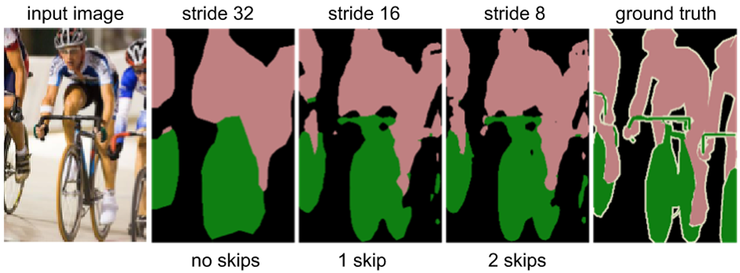
여러 단계의 결과를 합쳐주는 과정을 거치면 아래 그림과 같이 더 정교한 예측이 가능해지게 된다. stride가32인 경우는 자세하게 구별할 수 없지만, skip layer를 활용한 stride 8에서는 꽤 정교한 예측이 가능하게 된다.
3.4. Patchwise training is loss sampling
patchwise 훈련은 computational efficiency가 overlap 및 minibatch size에 의존하며, FCN 대비 연산량 또한 크다. 그러나 patchwise 훈련은 class imbalance를 수정하고 spatial correlation을 완화할 수 있는 장점이 있다. FCN은 이를 보완하기 위해 loss에 대한 가중치 적용을 통해 class imbalance를 해결하고, loss sampling을 통해 spatial correlation을 완화하였다.
4.3절에서 sampling을 통한 훈련으로 어떠한 나은점을 찾지 못하였고 따라서 FCN 팀은 전체 이미지에 대한 훈련이 더 효율적이라고 판단한다.
4. Segmentation Architecture
4.1. From classifier to dense FCN
FCN은 Semantic Segmentation 모델을 위해 기존에 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)에서 뒷단의 FCL에 1x1 conv를 적용하였다.
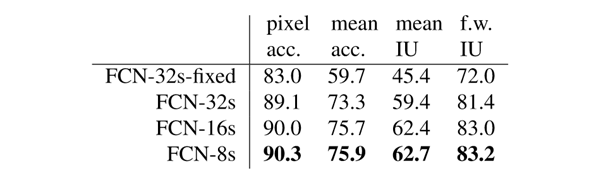
worst model도 기존 최고 성능 대비 75% 개선되었고 FCN-VGG16은 56.0 mean IU 라는 좋은 성적을 거뒀다.
결과는 아래와 같다.

4.2. Combining what and where
FCN에서는 1/32 크기에서의 feature(즉 score)만을 사용하는 것이 아니라, 1/16과 1/8에서의 값도 같이 사용하는 방식을 취하였다.
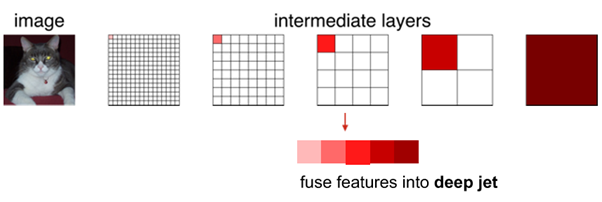
이것을 논문에서는 “deep jet”이라고 칭하였다. 이전 layer는 마지막 layer보다 세밀한 feature를 갖고 있기 때문에 이것을 합하면 보다 정교한 예측이 가능해진다. 1/16과 1/8 크기 정보를 이용하려면, 이후 (conv + pool) 단계를 거치지 않으면 된다. 즉, 건너 뛰면 되기 때문에 “skip layer” 혹은 “skip connection”이라고 부른다.
1/32에서 32배만큼 upsample한 결과를 FCN-32s라고 하며, FCN-16s는 아래 그림과 같이 pool5의 결과를 2배 upsample한 것과 pool4의 결과를 합치고 다시 그 결과를 16배 upsample하면 되고, FCN-8s는 FCN-16s의 중간 결과를 2배 upsample한 결과와 pool3에서의 예측을 합친 것을 8배 upsample 하는 식이다.
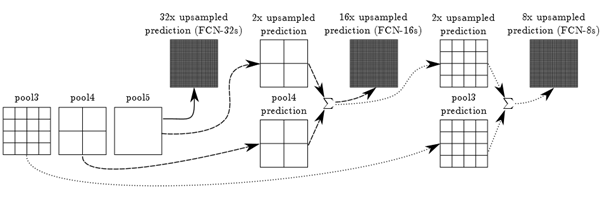
위 그림이 좀 복잡하기도 하고, 실제로 FCN의 결과는 주로 FCN-8s의 결과를 사용하기 때문에, FCN-8s만을 따로 표현을 해보면 아래와 같은 단순한 형태의 그림이 된다.
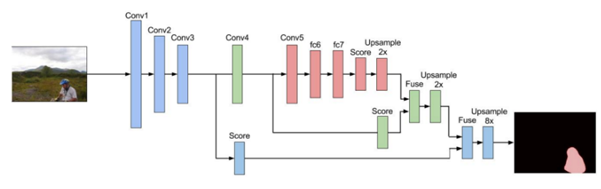
실제로 PASCAL VOC 2011 데이터를 이용하여 실험한 결과는 아래 표와 같다. FCN-32s 결과와 FCN-8s의 결과는 점차 개선되는 것을 확인할 수 있다.
4.3. Experimental framework
Optimization
- train by SGD with momentum
- minibatch size: 20images
- fixed learning rate: 10^-3(FCN-AlexNet), 10^-4(FCN-VGG16), 10^-5((FCN-GooLeNet)
- momentum: 0.8
- weight decay: 5^-4, 2^-4
- Zero-initialize
- Dropout
Fine-tuning
본 논문에서는 모든 net에 모든 layers에 대해 back-propagation을 통해 fine-tune 하였다. Output classifier에 대해서만 fine-tuning 수행시에도 표 2 기준 70%정도의 성능을 얻을 수 있다.
Patch sampling Class Balancing 생략
5. Results
아래 그림을 통해 FCN의 성능을 확인할 수 있다. 오른쪽에 있는 Image에 대하여 Ground Truth 값과 FCN을 통해서 얻을 결과를 비교하면, 꽤 괜찮은 성능을 얻을 수 있다는 것을 확인할 수 있다.

댓글남기기