
논문 링크 : https://arxiv.org/pdf/1703.06870.pdf
연관 논문 리뷰
R-CNN 계열 모델은 R-CNN, Fast R-CNN, Faster R-CNN, 그리고 Mask R-CNN까지 총 4가지 종류가 있다.
- R-CNN (2014): Rich feature hierarchies for accurate object detection and semantic segmentation
- Fast R-CNN (2015): Fast R-CNN
- Faster R-CNN (2016): Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Mask R-CNN (2017) : Mask R-CNN
R-1. R-CNN 요약
2013년 당시 버클리에 다니고 있던 Ross Girshick이 발표한 방법이다.
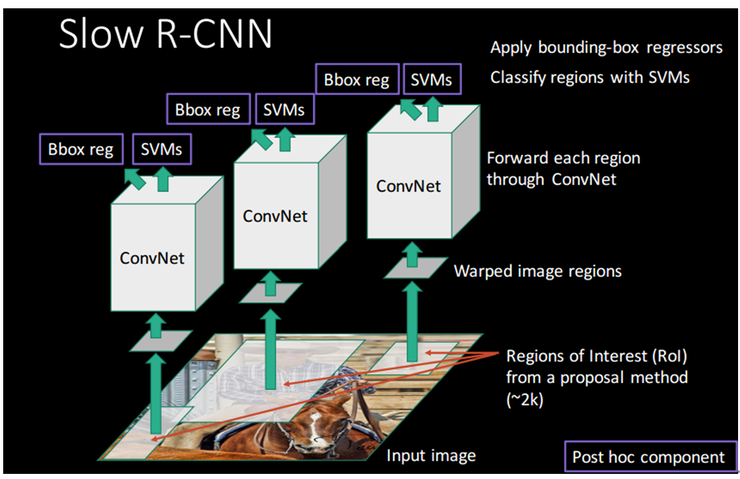
R-CNN 3단계 과정
- Region Proposal: selective search를 통해 Object가 있을 법한 2,000여 개의 region을 추출
- CNN: 각 region으로 부터 고정된 크기의 feature vector 추출
- SVM: classification 진행
3-1) Bbox reg: selective search로 만든 bbox가 정확하지 않기 때문에 정확히 감싸도록 조정해주는 bbox regression 사용
단점
- 단계 1에서 2,000여개의 region에 대해 CNN을 수행하기 때문에 CNN연산*2,000 만큼의 큰 수행시간 소요
- CNN, SVM, bbox reggressor의 3 단계 multi-stage pipelines으로 순차적으로 수행 각 Rogion proposal에 대한 ConvNet forward pass를 수행하는데 있어서 독립적이기 때문에 end-to-end로 학습할 수 없음 즉 SVM, bbox reg로부터 학습한 결과가 CNN을 업데이트 하기 못함.
그 외의 문제점
- Training 시간이 길고 대용량 저장 공간이 필요.
SVM과 bbox regressor의 학습을 위해, 영상의 후보 영역으로부터 feature를 추출하고 그것을 디스크에 저장 (PASCAL VOC07 학습 데이터 5천장에 대하여 2.5일 정도가 걸리며, 저장 공간도 수백 GigaByte를 필요) - 객체 검출(object detection) 속도가 느림.
학습이 오래 걸리는 문제도 있지만, 실제 검출할 때도 875MHz로 오버클럭킹된 K40 GPU에서 영상 1장을 처리하는데 47초 소요
이러한 문제점들을 RoI pooling으로 해결한 Fast R-CNN이 등장하다.
R-2. Fast R-CNN 리뷰
2015년 R-CNN을 발표한 Ross Girshick이 마이크로소프트로 자리를 옮겨 R-CNN 및 SPPNet의 문제를 개선한 Fast R-CNN을 발표한다.
Fast R-CNN은 기본적으로 검출 정확도(mAP)가 R-CNN이나 SPPNet보다는 좋으며, 학습 시 multi-stage가 아니라 single-stage로 가능하고, 학습의 결과를 망에 있는 모든 layer에 update할 수 있어야 하며, feature caching을 위해 별도의 디스크 공간이 필요 없는 방법을 개발하는 것을 목표로 삼았다.
기본 구조는 다음과 같다.
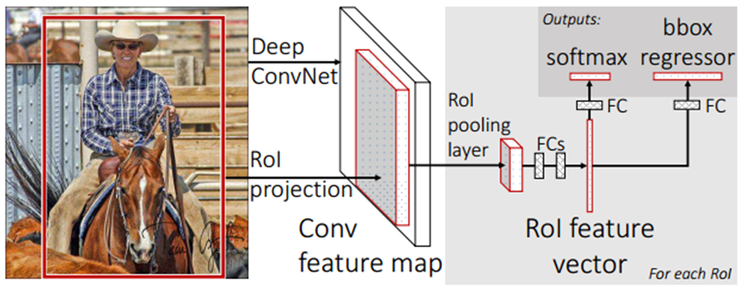
Fast R-CNN 수행과정 1-1. 전체 이미지를 미리 학습된 CNN에 통과시켜 feature map 추출 1-2. R-CNN에서와 마찬가지로 Selective Search를 통해 RoI 추출
- Selective Search로 찾았었던 RoI를 feature map 크기에 맞게 projection
- projection시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector를 얻는다.
- feature vector는 FC layer를 통과한 뒤, 두 브랜치로 나뉘게 된다. 5-1. softmax를 통과하여 RoI에 대해 object classification 수행 5-2. bbox regressor를 통해 selective search로 찾은 bbox 위치 조정
R-CNN의 구조와 비슷하게 표현된 아래의 그림을 보면 먼저 검출을 위한 test time시에 전체 영상에 대해 살펴보면,
ConvNet 연산을 1번만 수행하고 그 결과를 공유하며 RoI Pooling layer에서 다양한 후보 영역들에 대하여 FC layer에 맞게 크기를 조정해 준다. 이후 단계에서 Softmax classifier와 bbox regressor를 동시에 수행하기 때문에 빠르다.
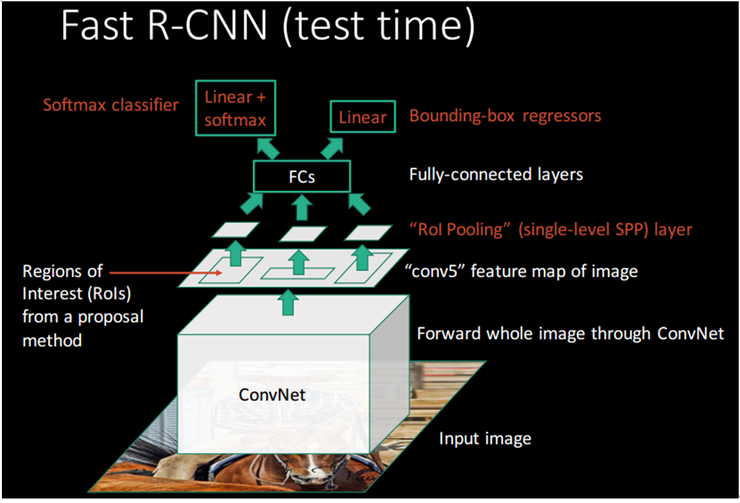
CNN을 한번만 통과시킨 뒤, 그 피쳐맵을 공유하는 것은 이미 SPPNet에서 제안된 방법이다. 아래의 training 과정을 보면 그 이후의 스텝들은 SPPNet이나 R-CNN과 그다지 다르지 않습니다. 그러나 Fast R-CNN의 가장 큰 특징은 이들을 multi-stage 로 진행하지 않고, end-to-end 진행하는데 있다. 그리고 그 결과로 학습 속도, 인퍼런스 속도, 정확도 모두를 향상시켰다는데 의미가 있다.
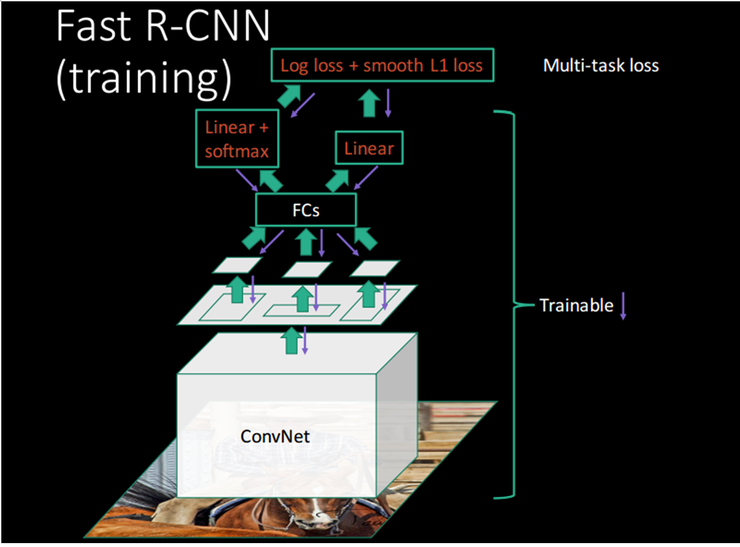
R-2. Faster R-CNN 리뷰
Faster R-CNN은 Ross Girshick이 실시간 객체 검출을 목표로 Fast R-CNN을 개선하여 발표한 논문이다.
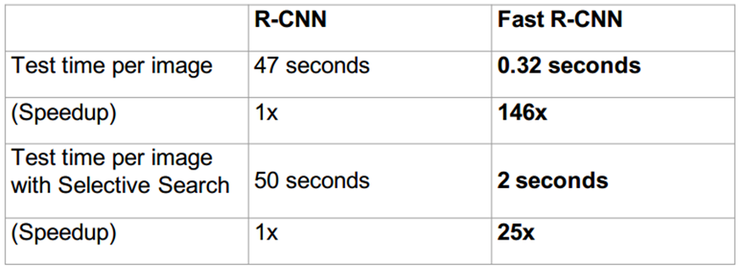
Fast R-CNN에서 R-CNN 대비 146x 라는 큰 속도 향상을 이루었지만 region proposal에 쓰인 selective search이 상당한 시간을 갖는것은 변함이 없어 병목구간이 된다. selective search의 문제점은 다음과 같이 정리된다.
- CPU에서 계산되기 때문에 속도가 느림
- CNN 외부에서 수행되기 때문에 전체에서 진정한 의미의 end-to-end는 아님.
selective search 방식을 자세히 살펴보면 아래 그림과 같다.
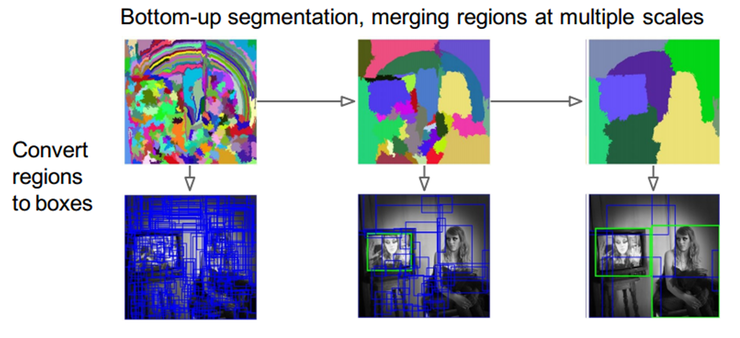
bottom-up segmentation을 수행하고 이것들을 다양한 scale 상에서 병합을 하고 이 region을 사각형 box 영역으로 구분하다. 전체적인 평가에서는 좋은 편에 속하지만, 연산 시간 관점에서는 좋은 방식이라 볼 수는 없다.
이러한 문제점을 해결하고자한 Faster R-CNN의 핵심 아이디어는 바로 Region Proposal Network(RPN)이다. 기존 Fast R-CNN 구조를 그대로 계승하며, selective search를 제거하고 RPN을 통해 RoI를 계산하다. 따라서 region proposal이 neural network에 들어가게 되며 진정한 의미의 end-to-end 모델이 되었으며, 전체를 GPU에서 연산 가능하게 되었다.
Faster R-CNN의 구조는 아래 그림과 같다.

feature map과 RoI pooling 사이에 RoI를 생성하는 RPN이 추가된 구조이다.
이 RPN은 Fast R-CNN에서 classification 및 bbox regressor에서 사용한 CNN 네트워크를 그대로 공유해서 사용하기 때문에 입력의 크기에 제한이 없으며, 모델은 FCN 형태이다. 개념도는 아래와 같다.

CNN을 통과하여 생성된 feature map을 RPN이 입력으로 받아 RoI를 생성하다. 여기서 주의할 점은 RoI는 feature map에서의 RoI가 아닌 original image에서의 RoI이다. 따라서 feature map에 맞게 RoI는 rescaling 된다.
결과는 성능면에서는 selective search를 별도로 사용하는 하지 않고 RPN을 사용하더라도 나쁘지 않았으며 연산 속도면은 아래와 같다.

VGG 모델기반에서 selective search + Fast R-CNN의 경우 0.5fps로 2초가 소요되지만 RPN을 사용할 경우 5fps로 0.2초가 소요된다. 조금 더 실시간의 영역에 근접해 간다.
Faster R-CNN까지는 모두 Object Detection을 위한 모델이었으나 Mask R-CNN은 Faster R-CNN을 확장하여 Instance Segmentation에 적용하고자 하는 모델이다. Mask R-CNN을 간략하게 요약한다면, Faster R-CNN에서 detect한 각각의 box에 mask를 씌워주는 모델이라고 생각할 수 있다.
Abstract
Mask R-CNN은 Faster R-CNN에 mask를 predict해주는 부분을 추가해준 것이다. 따라서 Faster R-CNN에 한 가지 부분만 추가해주면 되므로 학습하는 것이 간단하다.
또한 Mask R-CNN은 다른 tasks에도 쉽게 사용할 수 있다. (ex - human poses estimation) 일례로 COCO challenges의 모든 tasks (instance segmentation, bounding-box object detection, 그리고 person keypoint detection)에서 이전 모델보다 높은 성능을 보였다.
1. Introduction
Mast R-CNN는 기본적으로 Instance Segmentation을 하기 위한 모델이다.

지난 리뷰에서 FCN에서 semantic segmentation이 “주어진 이미지 안에 어느 특정 클래스에 해당하는 사물이 (만약 있다면) 어느 위치에 포함되어 있는지 ‘픽셀 단위로’ 분할하는 모델” 이라고 하였습니다. 즉 아래의 그림에서와 같이 사람을 따로 분류하지 않고 각 픽셀 자체가 어떤 class에 속하는지에만 관심이 있다.
instance segmentation은 같은 class이더라도 독립된 개체 즉, instance를 아래와 같이 구분하다.

Instance Segmentation을 하기 위해서는 Object detection과 semantic segmentation을 동시에 해야한다. 이를 위해 Mask R-CNN은 기존의 Faster R-CNN을 Object detection 역할을 하도록 하고 각각의 RoI (Region of Interest)에 mask segmentation을 해주는 작은 FCN (Fully Convolutional Network)를 추가해 주었다.
기존의 Faster R-CNN은 object detection을 위한 모델이었기 때문에 RoI Pooling 과정에서 정확한 위치 정보를 담는 것은 중요하지 않았다. RoI Pooling에서 RoI가 소수점 좌표를 갖고 있을 경우에는 각 좌표를 반올림한 다음에 Pooling을 해줍니다.
이렇게 되면 input image의 원본 위치 정보가 왜곡되기 때문에 Classification task에서는 문제가 발생하지 않지만 정확하게 pixel-by-pixel로 detection하는 segmentation task에서는 문제가 발생한다.
이를 해결하기 위해 Mask R-CNN에서는 RoI Pooling 대신에 RoI Align을 사용한다.
RoIAlign은 mask accuracy에서 큰 향상을 보였다고 한다.
Mask R-CNN의 두번째 핵심은 mask prediction과 class prediction을 decouple하였다는 점이다. 이를 통해 mask prediction에서 다른 클래스를 고려할 필요 없이 binary mask를 predict하면 되기 때문에 성능의 향상을 보였다고 한다.
아래 그림은 Faster R-CNN에 새롭게 추가된 부분을 잘 나타낸다.

2. Related Work
R-CNN과 Instance Segmentation에 대해서 간략히 소개하다. 앞에서 정리하였던 내용이니 넘어간다.
3. Mask R-CNN
Mask R-CNN은 Fast R-CNN과 마찬가지로 2 단계 procedure로 수행되며, 첫 단계는 RPN, 두 번째 단계는 class, box offset, binary mask 3개의 branch로 구성된 예측 단계로 이루어진다. mask branch는 기존은 Faster R-CNN이 수행하지 못했던 pixel-to-pixel alignment를 가능하게 한다.
학습동안에 각 RoI에 대해 병렬적으로 수행되는 multi-task loss를 정의한다.
\[L = L_{cls} + L_{box} + L_{mask}\]mask branch는 각 RoI에 대해 다음과 같은 output dimension을 가진다.
\[Km^2\]- K: class의 수
- m: m x m 오브젝트 mask 크기
기존 FCN의 경우 semantic segmentation을 위해 per-pixel softmax + multinomial cross-entropy loss를 사용하여 classification과 segmentation이 decoupling 되지 않는다.
mask R-CNN의 경우 per-pixel sigmoid + binary loss를 사용하므로써 classification과 segmentation이 decoupling 되어 더 좋은 instance segmentation 결과를 얻었다.
Mask R-CNN에서는 앞서 얘기한 바와 같이 RoI Pooling 대신에 아래와 같은 RoI Align을 사용하다. RoI Align는 mask의 feature map으로부터 subpixel 단위의 정확한 위치 정보를 계산하기 위해 bilinear interpolation을 사용하여 각 sampling point 값들을 계산한다.
RoIPool은 각 RoI로 부터 small feature map(예, 7x7)을 추출하는 전형적인 operation이다. small feature map 예로 7x7을 만들기 위해 stride=16을 사용하여 연속되는 좌표계인 x에 대해 [x/16]과 같이 Quantization 연산을 수행한다.([]: 소수 점 이하는 반올림 한다.) 이 때 RoI와 추출된 feature간에 misalignment가 발생한다. classification에서 이러한 misalignment는 큰 영향을 주지 않으나, 픽셀단위로 정확한 mask를 예측하는데에는 나쁜 영향을 주게된다.
이러한 이슈를 해결하기 위해 RoIAlign layer에서는 기존 [x/16] 연산에서 반올림 부분(harsh quantization)을 빼고 추출한 feature를 입력에 맞도록 aligning 한다(즉, x/16 사용). 제안된 방법은 다음과 같다. 각각의 RoI 영역에 대해 4개의 sample point에 대해 bilinear interpolation을 수행하고, 그 결과에 대해 max 또는 average로 합친다.

본 논문에서는 네트워크 구조에 대해 실험을 추가 진행하였다.
전체 네트워크 구조를 명확히 하기 위해 다음과 같이 구분하여 나타낸다.
- 전체 이미지에서 feature 추출에 사용되는 convolutional backbone 구조
- bounding-box recognition(classification, regression)을 위한 network head
- 각 RoI마다 개별적으로 적용되는 mask 예측
본 논문에서는 백본 (feature를 뽑기위한 베이스CNN)에 흔히 쓰는 ResNet과 함께, Feature Pyramid Network(FPN)를 소개한다. 각 backbone에 따른 network head는 아래와 같이 구성한다.

왼쪽의 ResNet C4(4번째 stage의 CN으로부터 feature 추출이라는 의미) backbone은 5번째 ResNet의 stage를 포함(res5)하며 이것은 계산 집약적이다. FPN backbone은 이미 res5를 포함하고 있어 적은 수의 필터를 사용하여 더 좋은 효과를 내는 head 구조가 가능하다.
COCO 이미지 데이터셋에서 결과는 아래와 같다.

백본을 FPN으로 세팅했을 경우의 결과가 가장 좋다. COCO이미지 데이터셋에서 MNC는 2015년, FCIS는 2016년 승자이며, FCIS+++는 각종 이미지 augmentation, online hard example mining 등을 통한 튜닝된 수치이다. 그럼에도 불구하고 싱글모델인 Mask R-CNN이 이 이상의 수치를 보여주는 것을 알수있다.
3.1 Implementation Details
Training
- resize: 800 pixel
- mini-batch: 2 images per GPU
- each image: has N sampled RoIs(ratio of 1:3 of positive to negatives.)
- c4 backbone N=64
- FPN backbone N=512
- train on 8 GPUs (mini-batch size=16) for 160k iterations
- learning rate: 0.02
- weight decay: 0.0001
- momentum: 0.9
4. Experiments: Instance Segmentation
COCO test image에 적용한 결과는 다음과 같다.

FCIS와 비교결과는 아래와 같다.

다음 그림은 mask prediction에서 binary mask(sigmoid)와 multinomial mask(softmax)를 사용했을 때의 결과를 비교한 것이다.

다음 그림은 RoIAlgin을 적용했을 때의 성능 향상을 보여준다.

5. Mask R-CNN for Human Pose Estimation
Mask R-CNN은 human pose estimation에 쉽게 확장이 가능하고 아래와 같은 결과를 보여준다.

댓글남기기