
논문 링크 : https://arxiv.org/pdf/1804.02767.pdf
연관 논문 리뷰
object detection 분야에 Faster-RCNN, MobileNet, SSD, YOLO 등 많은 모델이 있다. 이번 글은 YOLO 모델에 대해 살펴보겠다.
아래는 detection 분야의 네트워크들의 논문 리스트이다.

빨간 색은 지금까지의 핵심적인 논문들을 나타낸 것이다.
버전은 아래와 같다.
- YOLOv1 (2016): You Only Look Once: Unified, Real-Time Object Detection
- YOLOv2 (2017): YOLO9000: Better, Faster, Stronger
- YOLOv3 (2018): YOLOv3: An Incremental Improvement
Note IoU란?
Intersection over Union의 약자로 Detection 경우 사물의 클래스 및 위치에 대한 예측 결과를 동시에 평가해야 하기 때문에 bounding box와 class가 이미지 레이블 상에 포함되어 있으며, 실제(ground truth)와 모델이 예측한 결과(prediction)간의 비교를 통해 평가한다.
즉, 정확도가 높다는 것은 모델이 ground truth와 유사한 bounding box와 box 안의 object의 class를 잘 예측(Classification)하는 것을 의미한다.
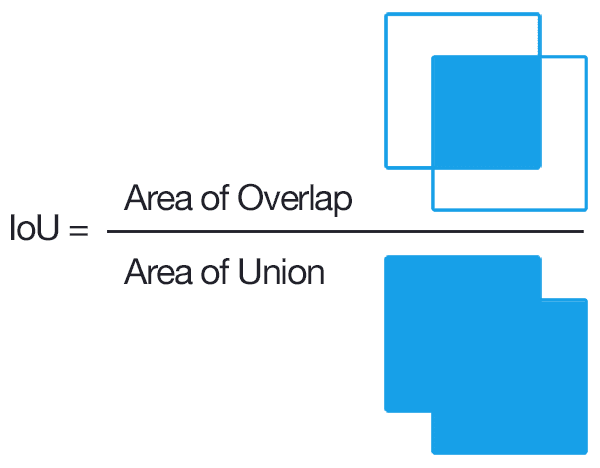
IoU는 교집합이 없는 경우에는 0을, ground truth와 prediction이 100% 일치하는 경우에는 1의 값을 가진다. 일반적으로 IoU가 0.5(threshold)를 넘으면 정답이라고 생각하며, 대표적인 데이터셋들마다 아래와 같이 다른 threshold를 사용한다.
- PASCAL VOC: 0.5
- ImageNet: min(0.5, wh/(w+10)(h+10))
- MS COCO: 0.5, 0.55, 0.6, .., 0.95
R-1. YOLOv1 요약
사람은 시야 안의 물체들에 대해 어떤 물체가 어디에 어떤 관계로 있는지를 바로 판단한다. 이와같은 인간의 시각체계와 비슷하게 동작하도록 single neural network로 설계한 모델이 YOLO 이다.
더 자세히 보면, R-CNN 시리즈는 2-stage method였고, SSD, YOLO는 1-stage method 이다. YOLO는 bounding box와 class probability를 동시에 예측하는 single regression problem으로 detection을 하고자 한다.

동작은 다음과 같다.
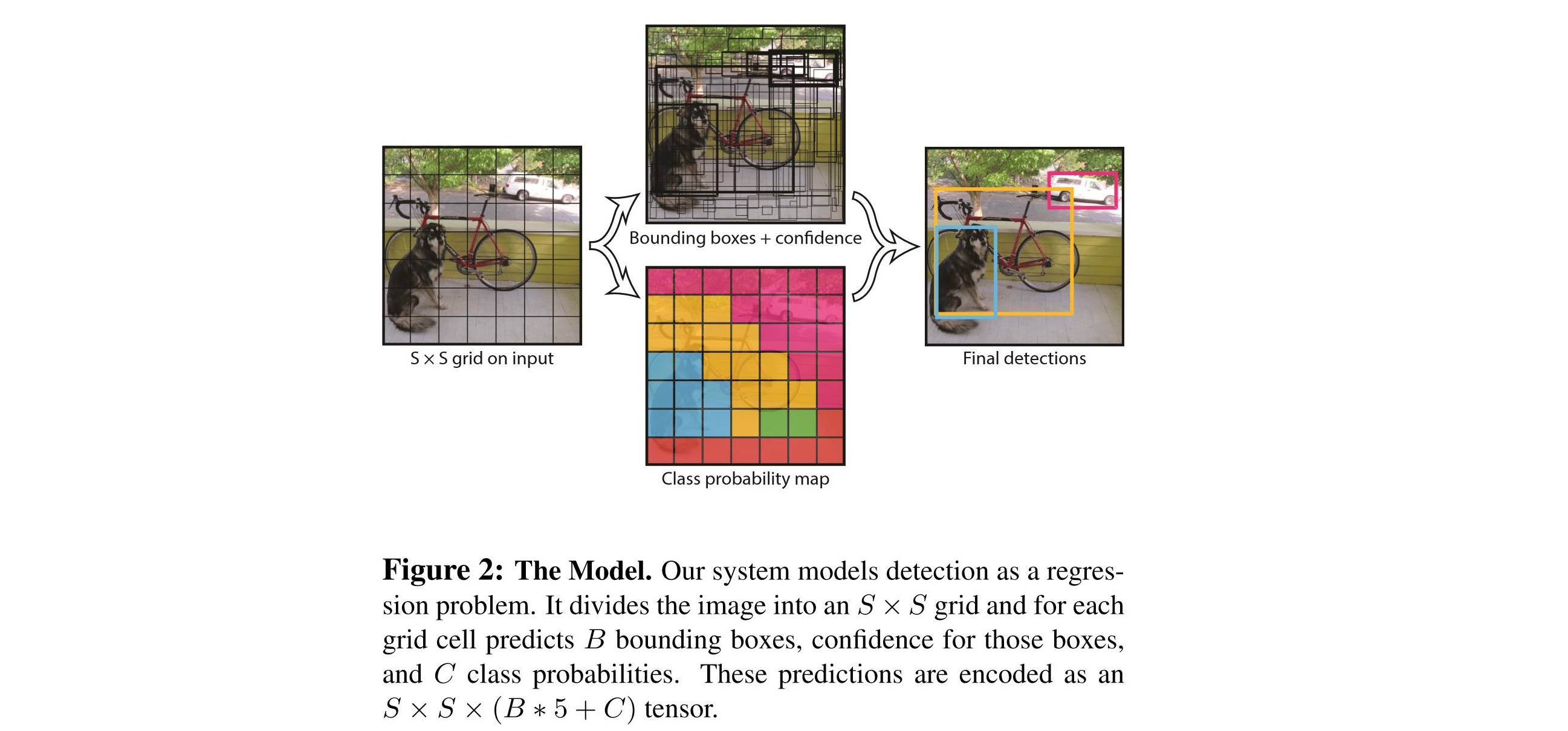
- Input image를 S X S grid로 나눈다.
- 각각의 grid cell은 B개의 bounding box와 각 bounding box에 대한 confidence score를 갖는다.
(만약 cell에 object가 존재하지 않는다면 confidence score는 0이 된다.)
Confidence Score: \(Pr(Object) * IOU_{pred}^{truth}\) - 각각의 grid cell은 C개의 conditional class probability를 갖는다.
Conditional Class Probability: \(Pr(Class_{i}|Object)\) - 각각의 bounding box는 x, y, w, h, confidence로 구성된다.
(x,y): Bounding box의 중심점을 의미하며, grid cell의 범위에 대한 상대값이 입력된다.
(w,h): 전체 이미지의 width, height에 대한 상대값이 입력된다.- 예1: 만약 x가 grid cell의 가장 왼쪽에 있다면 x=0, y가 grid cell의 중간에 있다면 y=0.5
- 예2: bbox의 width가 이미지 width의 절반이라면 w=0.5
Test time에는 conditional class probability와 bounding box의 confidence score를 곱하여 class-specific confidence score를 얻는다.
\[\begin{align} Class Specific Confidence Score &= Conditional Class Probability * Confidence Score \\ &= Pr(Class_{i}|Object) * Pr(Object) * IOU_{pred}^{truth} \\ &= Pr(Class_{i}) * IOU_{pred}^{truth}\\ \end{align}\]Non-maximal suppression
같은 객체에 대해 여러 개의 탐지(예측된 boundary boxes)가 있을 수 있다. 이것을 고치기 위해, YOLO는 더 낮은 confidence를 가진 중복된 것을 제거하는 non-maximal suppression을 적용한다.
구현 방법은 다음과 같다.
- confidence score 순으로 예측을 정렬한다.
- 제일 높은 score에서 시작해서, 이전의 예측 중 현재 예측과 클래스가 같고 IOU > 0.5인 것이 있었으면 현재의 예측은 무시한다.
- 모든 예측을 확인할 때까지 Step 2를 반복한다.
Network Architecture는 다음과 같다.

YOLO는 GoogLeNet for iamge classification 모델을 기반으로 inception 모듈 대신 간단하게 1x1 reduction layer와 3x3 Conv. layer를 사용하여 24 Conv. layer로 구성된다. 1x1 reduction layer를 통해 feature map의 깊이를 줄이고 2개의 fully-connected layer를 통해 regression을 수행하여 최종적으로 7x7x30 형태의 텐서를 만들어 낸다.
Fast YOLO의 경우 9 Conv. layer로 더 적은 layer를 사용하였으며 나머지 네트워크 크기나 최종 출력은 같다.
장점
- 다른 real-time detection system들과 비교해 비슷한 정확도 대비 처리 속도가 훨씬 빠름
- single neural network로 class에 대한 맥락적 이해도가 높아 backgound error(False-Positive)가 낮음
- Object에 대한 더 일반화된 특징 학습.(가령 natural image로 학습하고 이를 artwork에 테스트 했을때, 다른 Detection System들에 비해 훨씬 높은 성능을 보여줌)
단점
- 상대적으로 낮은 정확도
- 특히, 작은 물체 검출을 힘들어함.
R-2. YOLOv2 요약
논문의 제목(YOLO9000: Better, Faster, Stronger)에 맞게 크게 3부분에 대해 개선하였다.
- Better: Accuracy, mAP 측면의 개선
- Faster: 속도 개선
- Stronger: 더 많은, 다양한 클래스 예측
Better
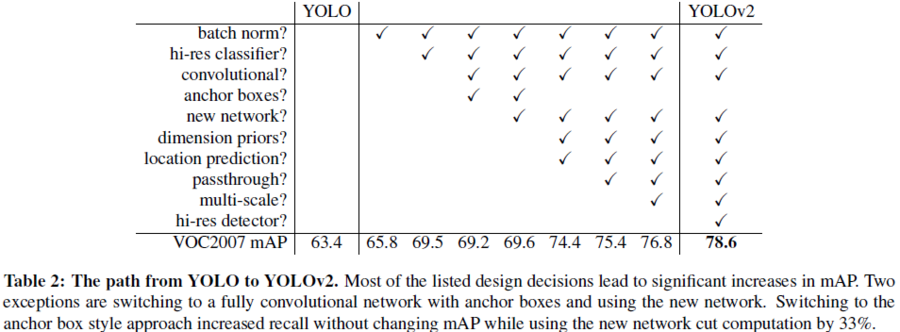
성능 향상 방법들은 아래와 같다.
- Batch Normalization: 모든 convolution layer에 배치 정규화를 추가 -> 2% mAP 향상
- High Resolution Classifier: ImageNet 데이터로 앞단의 classification network를 먼저 학습시켜서 고해상도 이미지에도 잘 동작
(448x448의 해상도로 10 epoch 동안 fine tuning함. 그리고 나머지 부분들을 디텍션하면서 tuning) -> 4% mAP 향상 - Convolutional: fully-conneted layer를 convolution layer로 대체 -> 계산량 33% 감소
- Anchor Boxes: 앵커 박스를 초기값으로 사용하여 예측 -> 3,4로 mAP는 0.3% 만큼 줄어들었지만 recall이 81%에서 88%로 증가.
- Dimension Clusters: 실제 경계 박스들을 클러스터링하여 최적의 앵커박스를 찾음(k-means 알고리즘 사용)
- Direct location prediction: 경계 박스가 그리드 셀에서 벗어나지 않게 제약을 둠 -> 5,6로 인해 5% mAP 향상
- Passthrough: 26x26 크기의 중간 특징맵을 skip 하여 13x13layer에 붙임(concatenate) -> 6, 7로 1% mAP 향상
- Multi-Scale Training: 학습데이터의 크기를 320x320, 352x352, …, 608x608 로 resize 하면서 다양한 스케일로 학습시킴
- Fine-Grained Features: 최종 특징맵의 크기를 7x7에서 13x13으로 키움
다음은 위의 10가지 요인에 따른 성능 향상을 비교하여 보여준다.
Faster
- New network(Darknet-19): Image detection 모델의 앞단에 있는 classifier network로 VGG Net을 많이 쓴다. 하지만 VGG-16은 224x224 해상도에서 30.69십억의 floating point 계산을 필요로 한다.YOLOv2에서는 GoogLeNet을 기반으로한 독자적인 Darkent을 만들어 계산량을 8십억으로 줄였다. (accuracy: 88%, VGG-16의 accuracy: 90%로 크게 차이 나지 않음)
- Training for classification: ImageNet 1000개 클래스 구별 데이터셋을 160 epoch동안 학습하면서 learning rate = 0.1, polynomial rate decay = a power of 4, weight decay = 0.0005, momentum = 0.9, 처음 튜닝은 224로 하다가 중간에 448로 fine tune.
- Training for detection: 5 bounding box로 5개의 좌표(Confidence score + coordinate)와 20개의 class 점수를 예측하므로 한 그리드 셀에서는 총 5x(5+20) = 125개의 예측값을 가지게 된다. 또 중간에 pass-through layer로부터(26x26) concatenate된 예측값도 포함. 160 epoch동안 10^(-3)에서 시작하여 10, 60, 90 에폭마다 decay하고, weight decay = 0.0005, momentum = 0.9를 사용했다. data augmentation 역시 random crops, color shifting등을 이용했다.
Stronger
Image classification은 클래스가 몇천~몇만개정도로 많지만 detection의 라벨은 20~몇 백개 정도가 전부이다. 이런 갭을 완화하기위한 전략을 다음과 같이 사용하였다.
- trining때 classification과 detection data를 섞어서 사용(Hierarchical classification, Dataset combination with WordTree, Joint classification and Detection)
- data set에서 detection data가 들어오면 원래 loss function을 활용해 계산
- data set에서 classification data가 들어오면 loss function에서 classification loss만 활용해 계산
- classification loss 계산시 ground truth label의 그 계층이나 상위계층만 backprop하고 아래 계층에 내려가지 못하도록 아래 계층에 대한 예측할 시 error 부과.
검출 성능이 19.7% mAP, 학습과정에서 전혀 본적이 없는 156개의 클래스를 포함하면 16.0% mAP. 그래도 다른 DPM(object detection with discriminatively trained part based models)보다는 좋은 성능.
Abstract
YOLOv2 조금 더 개선시킨 버전으로 이전 모델보다 network의 크기는 조금 더 커지고 성능은 향상되었다. 또한 320x320 YOLOv3 기준 28.2 mAP로 SSD만큼의 accuracy를 갖지만 속도는 22ms로 3배 더 빠르다. 0.5 IoU mAP detection metric YOLOv3의 성능이 상당히 좋았으며 Titan X에서 RetinaNet이 57.5 \(AP_{50}\), 198ms 속도였던 반면, 57.9 \(AP_{50}\), 51ms 로 3.8배 속도가 더 빨랐다.
1. Introduction
YOLOv3는 성능은 개선시켰지만 특별히 흥미가 될만한 큰 기술의 변화는 없다. 따라서 본 논문은 연구를 위해 시도했던 다양한 방법들을 기술한 tech report 형식으로 작성되었다.
먼저 2절에서 YOLOv3의 개선 방법에 대해 설명하고 3절에서 시도했으나 성공하지 못했던 방법들을 기술한다. 마지막으로 기술한 내용들의 의미를 살펴본다.
2. The Deal
다른 사람들의 아이디어를 사용하여 YOLOv2 개선 시킨 내용을 기술한다.
2.1. Bounding Box Prediction
YOLOv2에서 도입한 anchor box는 초기 regression 학습을 안정화 시키는 역할을 한다. anchor가 없으면 초기에 아무런 정보없이 object의 크기를 예측해 나가기 때문에 정밀하게 맞출 수는 있겠지만 학습이 오래걸린다. 이러한 이유로 초기 정의된 크기의 box들을 설정하여 초기학습을 안정화시킨다.
YOLOv3도 YOLOv2와 마찬가지로 anchor box를 dimension cluster로 사용하여 bounding box를 예측한다. 아래의 4개 좌표(\(t_x\), \(t_y\), \(t_w\), \(t_h\))를 예측하여 bounding box 계산한다.
또한 학습에서 SSE(Sum of Squared Error)를 loss로 사용한다. 만약 특정 좌표 예측을 위한 ground truth가 \(\hat{t}_*\) 이고, 예측이 \(t_*\) 일 때 gradient는 다음과 같다.
\[gradient = \hat{t}_* - t_*\]이 때 \(t\)는 기존의 식에 inverse를 취해서 ground truth \(t\) = \((t_x, t_y, t_w, t_h)\)를 계산
- \(t_x\) = \(\sigma^{-1} (b_x-c_x)\)
- \(t_y\) = \(\sigma^{-1} (b_y-c_y)\)
- \(t_w\) = \(ln (b_w / p_w)\)
- \(t_h\) = \(ln (b_h / p_h)\)
YOLOv3는 또한 logistic regression을 사용하여 각 bounding box에 대한 objectness score를 예측한다. 어느 한 bounding box가 다른 bounding box들 보다 더 많이 겹쳐진 경우 그 값이 1이 된다.(즉, 가장 IoU값이 큰 값을 1로 설정한다). 제일 많이 겹쳐진 box가 아니지만 일정 threshold 이상 겹쳐진 box들은 유추에서 무시되고(threshold를 0.5 사용), 이렇게 무시된 box들은 coordinate와 class prediction의 loss는 0으로 간주되며 objectness loss만 계산한다.
2.2. Class Prediction
YOLOv2는 사용한 softmax는 ‘woman’과 ‘person’ 같이 배타적이지 않은 multi-label도 있으므로 비효율적이다. 따라서 YOLOv3에서는 각각의 label에 대하여 independent logistic classifier를 사용하였다. loss term 역시도 binary cross entropy 바꾸어 학습하였으며, threshold를 설정하여 multi-label classification 수행하였다. 이는 좀 더 복잡한 데이터 셋(특히, multi-label에 해당되는 셋)을 학습하는데 좋았다고 한다.
2.3. Predictions Across Scales
YOLOv3는 3개의 다른 scale의 box를 예측한다. feature pyramid network의 concept과 유사하게 이 3개의 scale에서 feature들을 추출한다.
먼저, 기존의 feature extractor에 몇 개의 convolution layer를 추가하였고, 3D tensor 유추하는데 여기에는 bounding box와 objectness와 class 예측에 대한 정보가 포함되어있습니다. 실험에서는 COCO에 각 스케일마다 3개의 박스를 유추하도록 하여 텐서의 크기는 \(N x N x [3 * (4 + 1 + 80)]\)이다.
다음으로는 2개 이전의 layer로부터 feature map를 가져와 그것을 2배로 upsampling하고, 그 이전의 feature map을 가져와 서로 더해줍니다(ResNet의 skip-connetion을 추가한 걸로 보이네요.). 여기에 몇개의 convolutional layer를 붙여 이전과 동일하면서 크기는 2배인, 다른 스케일에서의 tensor를 예측하게 된다.
이런 작업을 한번 더 하여 마지막 스케일까지 완성합니다.
여전히 k-means clustering을 통해 bounding box 우선 순위를 정하고, 9개의 cluster와 3개의 scale을 임의로 선택한 다음 클러스터를 여러 scale로 균등하게 나눈다.
2.4. Feature Extractor
OLOv2에 최근의 ResNet을 합쳐 새로운 네트워크를 만들었다. 3x3과 1x1의 컨볼루셔널 레이어가 반복되고 거기에 skip-connection을 갖도록 하여 53개의 컨볼루셔널 레이어를 갖는 Darknet-53을 제안하였다.
이 네트워크는 Darknet-19보다 강력하면서도 ResNet-101, ResNet-152보다 더 효율적이다.


2.5. Training
하드 네거티브 마이닝과 같은 방법 없이 전체 이미지를 모두 사용하였으며 multi-scale training, data augmentation, batch normalization 등의 기존의 기법을 사용하였따.
3. How We Do
COCO의 average mean AP(\(AP_M\)) metric에서 SSD 수준이지만 3배 더 빠르며, RetinaNet보다 살짝 못한 수준이다.
하지만 기존의 IoU = 0.5(\(AP_{50}\))에서의 mAP를 측정하면 YOLOv3는 매우 좋은 성능을 보인다. 이로 볼 때 YOLOv3는 매우 강력한 검출기이나 IOU treshold를 증가시킬 수록 성능이 저하됨을 알 수 있다.
이전의 YOLO는 작은 물체를 검출하기가 어려웠는데, 이제는 작은 객체에서도 \(AP_S\) 성능이 향상됬지만, 아직 중간 크기와 큰 크기에서 비교적 성능이 낮은편입니다.
만약 IOU = 0.5(\(AP_{50}\))에서 속도 대비 성능으로 평가한다면 YOLOv3가 다른 시스템보다 빠르면서도 더 좋은 성능을 보일 수 있습니다.

4. Things We Tried That Didn’t Work
Anchor box x, y offset predictions.
linear 활성 함수를 사용하여 box 크기의 배수로 x, y offset을 유추하는 방법을 사용했으나 didn’t work!
Linear x, y predictions instead of logistic
Logistic 활성 함수 대신 x,y offset을 직접 유추하기 위해 linear 활성 함수 사용을 시도해 보았으나 mAP를 매우 떨어트렸다. didn’t work!
Focal loss
focal loss를 시도해보았는데, mAP를 2 point나 떨어트렸다. didn’t work!
RetinaNet에서 제안한 것으로 background와 object에 대한 loss를 분리하여 적용하나, YOLO 는 background class가 없으며 이미 loss를 분리하여 적용하므로 큰 효과 없음.
Dual IOU thresholds and truth assignment
Faster R-CNN은 두개의 IOU를 사용하여 오버랩이 0.7이 넘는 경우에는 positive 샘플로, [0.3, 0.7]에서는 무시하고, 0.3 이하는 네거티브 샘플로 사용한다. 비슷한 전략을 사용해봤지만 didn’t work!
5. What This All Means
위의 결과를 다시 보자. 테이블을 보면 YOLOv3이 전체적으로 뛰어나지 않아 보일 수 있다. 그러나 Russakovsky et al에 따르면 사람도 IoU .3과 IoU .5를 구분하기 어려워한다고 한다.
old metric에서 현제의 metric으로 바뀜에 따라 지금의 metric에 맞춰 개선하는것의 의미에 대해 저자는 의문을 갖는다.
자세한 내용은 본문을 참고하길 바란다.
Reference
댓글남기기